
I remember getting my first “Embedded Interview” after countless hours of CV editing, formatting and writing customized cover letters while applying to Job portals and startup websites. It was exciting all nevertheless the pressure to ace my interview got me wishing if I could read Minds like Xavier!!!
Though, wishful thinking didn’t help me at all!!!
What really helped me were a compilation of my university scrapbooks and online blogs to get my technical basics right, so this post is about list of questions which might help individuals whether freshers or little seasoned Engineers who are preparing for their Interviews.
I hope these embedded system interview questions and answer will be helpful to you. If you have any other important questions related to the embedded systems and concepts or have better answers, then please write in the comment box. I will make sure to add edits.

Content
- Embedded C Interview Questions for Freshers.
- What are the components of an Embedded system?
- Difference Between RISC and CISC Processor?
- Difference between Von-Neuman and Harvard Architecture?
- Difference between BJT and MOSFET?
- Difference Between Microcontroller and Microprocessor?
- What is the Difference between Oscillator and Crystal Oscillator?
- What are the different types of Buses used by Embedded Systems?
- What is the boot-loader?
- Difference between UART, SPI and I2C?
- List various timers in embedded systems?
- Explain what is a Watchdog Timer?
- What is the need of pull up and pull down resistor in circuit?
- Embedded C Programming Interview Questions.
- Difference between C and Embedded C?
- Difference between compiler and interpreter?
- Difference between while(1) and while(0) in C language?
- Difference Between Structure and Array in C?
- Difference Between Structure and Union in C?
- Explain What Are The Different Storage Classes In C?
- Explain What Are The Different Qualifiers In C?
- What Is Pass By Value And Pass By Reference?
- Which statement is faster ++I or i+1?
- Embedded C Interview Questions for Experienced Engineers.
- What do you understand by startup code?
- Functions of Startup file?
- What are the differences between process and thread?
- What is ISR?
- Role of Interrupt Vector Table in Interrupt Processing?
- Explain What Is Interrupt Latency? How Can We Reduce It?
- What are the uses of the Keyword Static?
- What does “const int x;” mean?
- Where are constant variables stored in memory?
- How can you protect a character pointer by some accidental modification with the pointer address?
- Can a variable be volatile and const both?
- What is a Null pointer?
- What is the size of a pointer?
- When does a segmentation fault occur?
- What Is Difference Between Using A Macro And Inline Function?
- How can you use a variable in a source file defined in another source file?
- Little and Big Endian Mystery
- List the 4 levels of testing in Embedded Systems.
- What is multithreading and multiprocessing?
- What is Mutex?
- What is Semaphore?
- What are the 2 types of Semaphore?
- Is there any difference between Deadlock and Starvation?
- Difference between RS232 and RS485 (RS232 vs RS485)?
- What is CAN?
- Why CAN?
- Standard CAN vs Extended CAN
- How do CAN bus modules communicate?
- Why Can Is Having 120 Ohms At Each End?
Embedded C Interview Questions for Freshers
1.1 What are the components of an Embedded System?
As the embedded system is made up of hardware and software components. In below section hardware components are described below:
- Power supply
- Processor
- Memory
- Timers counters
- Communication ports
- Output and Input
- Circuits used in application
When all the hardware components are selected for an embedded system the next task is to select software components for designing an embedded system.
- Assembler
- Emulator
- Debugger
- IDE and Compiler
1.2 Difference Between RISC and CISC Processor?
The Major Difference Between RISC and CISC is that RISC and CISC are the computer instruction sets which is a part of computer architecture. The Key Difference Between RISC and CISC is in the number of computing cycles each of their instructions take.
| Basis of Comparison | RISC | CISC |
|---|---|---|
| Acronym | RISC stands for Reduced Instruction Set Computer | CISC stands for Complex Instruction Set Computer |
| Definition | RISC processors have simple instructions taking about one clock cycle. The average Clock cycles Per Instruction(CPI) of a RISC processor is 1.5 | CISC processors have complex instructions that take up multiple clock cycles for execution. The average Clock cycles Per Instruction of a CISC processor is between 2 and 15 |
| Memory unit | There are hardly any instructions that refer memory. | Most of the instructions refer memory |
| RISC processors have a fixed instruction format | CISC processors have variable instruction format. | |
| The instruction set is reduced i.e. it has only few instructions in the instruction set. Many of these instructions are very primitive. | The instruction set has a variety of different instructions that can be used for complex operations. | |
| RISC has fewer addressing modes and most of the instructions in the instruction set have register to register addressing mode. | CISC has many different addressing modes and can thus be used to represent higher level programming language statements more efficiently. | |
| Complex addressing modes are synthesized using software. | CISC already supports complex addressing modes | |
| Multiple register sets are present | Only has a single register set | |
| Pipelining | RISC processors are highly pipelined | They are normally not pipelined or less pipelined |
| The complexity of RISC lies in the compiler that executes the program. | The complexity lies in the micro program | |
| Applications | The most common RISC microprocessors are Alpha, ARC, ARM, AVR, MIPS, PA-RISC, PIC, Power Architecture, and SPARC. | Examples of CISC processors are the System/360, VAX, PDP-11, Motorola 68000 family, AMD and Intel x86 CPUs. |
1.3 Difference between Von-Neuman and Harvard Architecture?
| Basis of Comparison | Von Neumann | Harvard Architecture |
|---|---|---|
| Definition | The Von Neumann architecture is a style of computer architecture that is straightforward and makes use of a single memory connection. | The Harvard Architecture is the current design standard, and it features RAM and ROM that are kept completely independent. |
| Design | The layout is straightforward and makes use of the same path to both store data and take instructions. | When compared to the Von Neumann architecture, this design is more complicated because it utilizes separate connections for RAM and ROM. |
| Hardware | When compared to Harvard Architecture, the hardware requirements are significantly lower. | When compared to the Von Neumann Architecture, the Harvard Architecture places a greater emphasis on the use of hardware. |
| Speed | In comparison to the Harvard Architecture, the speeds of the processors are significantly lower. | Harvard Architecture is faster than the others. A computer modelled are significantly lower. after the Harvard Architecture calls for an increase in the available space. |
| Physical space | When compared to the Harvard Architecture computers, the Von Neumann computers have a smaller footprint in terms of the required amount of physical space. | In Harvard Architecture, the requirement for the actual space is increased. |
| Internal memory | Because the memory and the programmes share the same space, there is no unused space in the internal memory. | Because the instruction memory and the data memory cannot share the same space, some of Harvard’s internal memory is going to waste somewhere. |
| Running Instructions | The instructions for running can either be taken from the programme that has been stored or they can be given explicitly. As a result, the two cannot be considered together. | Due to the fact that the input and the programme instructions that are stored in the programme are taken simultaneously, the running instructions are somewhat complicated and somewhat slow. |
1.4 Difference between BJT and MOSFET?
| Parameter | BJT | MOSFET |
|---|---|---|
 |  | |
| Full form | BJT stands for Bipolar Junction Transistor. | MOSFET stands for Metal Oxide Semiconductor Field Effect Transistor. |
| Definition | BJT is a three-terminal semiconductor device used for switching and amplification of signals. | MOSFET is a four-terminal semiconductor device which is used for switching applications. |
| Types | Based on the construction, BJTs are classified into two types: NPN and PNP. | Based on the construction and operation, the MOSFETs are classified into four types: P-channel enhancement MOSFET, N-channel enhancement MOSFET, P-channel depletion MOSFET and N-channel depletion MOSFET. |
| Terminals | BJT has three terminals viz. emitter, base and collector. | MOSFET has four terminals, i.e., source, drain, gate and body (or substrate). |
| Charge carriers | In BJT, both electrons and holes act as charge carriers. | In MOSFET, either electrons or holes act as charge carriers depending on the type of channel between source and drain. |
| Polarity | BJT is a bipolar device. | MOSFET is a unipolar device. |
| Controlling quantity | BJT is a current controlled device. | MOSFET is a voltage controlled device. |
| Input impedance | BJT has low input impedance. | MOSFET has relatively high input impedance. |
| Temperature coefficient | BJT has negative temperature coefficient. | MOSFET has positive temperature coefficient. |
| Switching frequency | The switching frequency BJT is low. | For MOSFET, the switching frequency is relatively high. |
| Power consumption | BJT consumes more power than MOSFET. | The power consumed by a MOSFET is less than BJT |
| Applications | BJT is preferred for the low current applications. It is widely used as amplifiers, oscillators and electronic switches. | MOSFET is suitable for high power applications. It is used in power supplies, etc. |
1.5 Difference Between Microcontroller and Microprocessor?
| Microcontroller | Microprocessor |
|---|---|
 |  |
| The microcontroller is the heart of an embedded system. | The microprocessor is the heart of a Computer system. |
| The microcontroller has an external processor along with internal memory and i/O components | It is just a processor. Memory and I/O components have to be connected externally |
| Since memory and I/0 are present internally, the circuit is small. | Since memory and I/O have to be connected externally, the circuit becomes large. |
| Can be used in compact systems and hence it is an efficient technique | Cannot be used in compact systems and hence inefficient |
| The cost of the entire system is low | Cost of the entire system increases |
| Since external components are low, total power consumption is less and can be used with devices running on stored power like batteries. | Due to external components, the entire power consumption is high. Hence it is not suitable to used with devices running on stored power like batteries. |
| Most of the microcontrollers have power-saving modes like idle mode and power-saving mode. This helps to reduce power consumption even further. | Most microprocessors do not have power-saving features. |
| Since components are internal, most of the operations are internal instruction, hence speed is fast. | Since memory and I/O components are all external, each instruction will need an external operation, hence it is relatively slower. |
| Microcontrollers have more number of registers, hence the programs are easier to write. | Microprocessors have less number of registers, hence more operations are memory based |
| Microcontrollers are based on Harvard architecture where program memory and Data memory are separate | Microprocessors are based on the von Neumann model/architecture where programs and data are stored in the same memory module |
| Used mainly in washing machines, MP3 players | Mainly used in personal computers |
1.6 What is the Difference between Oscillator and Crystal Oscillator?
An oscillator is any device or circuit that generates a periodically oscillating electric signal (usually a sine wave or a square wave). One example is the parallel LC oscillator:
A crystal is a piece of piezoelectric material that generates an oscillating sinusoidal electric signal due to the mechanical vibration of its structure. Crystals vibrate at very precise frequencies, so they produce precisely tuned outputs.
1.7 What are the different types of Buses used by Embedded Systems?
- Memory Bus: It is related to the memory-connected processor.
- Multiplexed Bus: It reads and writes in memory.
- De-multiplexed Bus: It contains 2 wires in the same bus. One has the address, and the other contains the data.
- Input/Output Bus: It multiplexes the same input and output signals by using multiplexing techniques.
1.8 What is the boot-loader?
In general, a bootloader is a code that executes at the instant the CPU comes out of reset until it passes off control of the system to the OS. It performs basic initialization of the CPU and sometimes some other peripheral devices, such as disk subsystems, sometimes network controllers, perhaps timers, DMA controller, video controller, UART(s), etc. Sometimes it can have an interactive component, or it might be completely invisible.
In Non-OS MCU you can create your own bootloader (basically an application) to check the integrity of the image and with some require initialization. You can also upgrade the image using the help of a bootloader application.
1.9 Difference between UART, SPI and I2C?
| Features | UART | SPI | I2C |
|---|---|---|---|
| Full Form | Universal Asynchronous Receiver/Transmitter | Serial Peripheral Interface | Inter-Integrated Circuit |
| Interface Diagram | 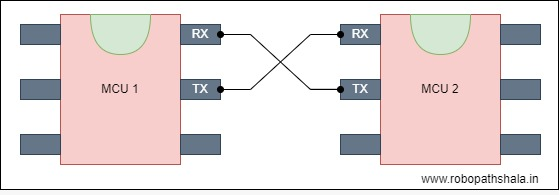 |  | 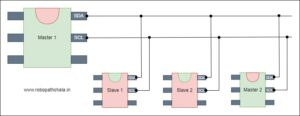 |
| Pin Designations | TxD: Transmit Data RxD: Receive Data | SCLK: Serial Clock MOSI: Master Output, Slave Input MISO: Master Input, Slave Output SS: Slave Select | SDA: Serial Data SCL: Serial Clock |
| Data rate | Asynchronous communication, with data rate around 230 Kbps to 460 Kbps | Maximum data rate not specified, typically supports 10 Mbps to 20 Mbps | Supports various speeds including 100 kbps, 400 kbps, and 3.4 Mbps, with some variants supporting 10 Kbps and 1 Mbps |
| Distance | Lower (about 50 feet) | Higher | Higher |
| Type of communication | Asynchronous | Synchronous | Synchronous |
| Number of masters | Can connect only two devices at a time | One | One or more than One |
| Clock | No common clock signal, independent clocks for each device | Common serial clock signal between master and slave devices | Common clock signal between multiple masters and multiple slaves |
| Hardware complexity | Lesser | Less | More |
| Protocol | Each company or manufacturer may have specific protocols; typically uses start and stop bits, and ACK bit for data acknowledgment | Uses slave select lines for addressing; typically uses push-pull for higher data rates | Uses open collector bus concept; addressing is simpler; supports flow control |
| Software addressing | Not needed due to one-to-one connection | Uses slave select lines for addressing | Simple addressing mechanism; supports multiple slaves and masters |
Advantages
- UART:
- Simple and popular, widely available.
- Supports full duplex communication.
- SPI:
- Simple protocol with no processing overheads.
- Supports higher data rates and longer ranges.
- Requires fewer wires for communication.
- Supports more than one master.
- I2C:
- Simple addressing mechanism.
- Easy to add extra devices on the bus.
- Supports multiple slaves and masters.
Disadvantages
- UART:
- Suitable for communication between only two devices.
- SPI:
- Fixed data rate agreed upon initially.
- Hardware complexity increases with the number of slave devices.
- I2C:
- Half duplex interface.
- Requires software stack for protocol control.
1.10 List various timers in embedded systems?
- Watchdog Timer (WDT)
- General Purpose of Timer
- Interval Timer (Programmable timer)
- Systick Timer
- Real-Time Clock (RTC)
1.11 Explain what is a Watchdog Timer?
A watchdog timer (WDT) is a hardware timer that automatically generates a system reset if the main program neglects to periodically service it. It is often used to automatically reset an embedded device that hangs because of a software or hardware fault. Some systems may also refer to it as a computer operating properly (COP) timer. Many microcontrollers including the mbed processor have watchdog timer hardware.
1.12 What is the need of pull up and pull down resistor in circuit?
Pull-up resistors are resistors which are used to ensure that a wire is pulled to a high logical level in the absence of an input signal.

Pull-down resistors work in the same manner as pull-up resistors, except that they pull the pin to a logical low value.

Embedded C Programming Interview Questions
2.1 Difference between C and Embedded C?
| Parameters | C | Embedded C |
|---|---|---|
| GENERAL | It is a structural and general purpose programming language used by the developers to build desktop-based applications. | Embedded C is generally used to develop microcontroller-based applications. |
| DEPENDENCY | C language is hardware independent language. C compilers are OS dependent. | Embedded C is fully hardware dependent language. Embedded C are OS independent. |
| COMPILER | For C language, the standard compilers can be used to compile and execute the program. Popular Compiler to execute a C language program are: GCC (GNU Compiler collection) Borland turbo C, Intel C++ | For Embedded C, a specific compilers that are able to generate particular hardware/micro-controller based output is used. Popular Compiler to execute a Embedded C language program are: Keil compiler BiPOM ELECTRONIC Green Hill software |
| USABILITY AND APPLICATION | C language has a free-format of program coding.It is specifically used for desktop application.Optimization is normal. It is very easy to read and modify the C language.Bug fixing are very easy in a C language program. It supports other various programming languages during application.Input can be given to the program while it is running. Applications of C Program: Logical programs System software programs | Formatting depends upon the type of microprocessor that is used. It is used for limited resources like RAM and ROM.High level of optimization. It is not easy to read and modify the Embedded C language. Bug fixing is complicated in a Embedded C language program. It supports only required processor of the application, and not the programming languages. Only the pre-defined input can be given to the running program. Applications of Embedded C Program: DVD TV Camera |
2.2 Difference between compiler and interpreter?
A compiler takes the source code as a whole and translates it into object code all in one go. Once converted, the object code can be run at any time. This process is called compilation.
An interpreter translates source code into object code one instruction at a time. It is similar to a human translator translating what a person says into another language, sentence by sentence. The resulting object code is then executed immediately. The process is called interpretation.
2.3 Difference between while(1) and while(0) in C language?
Let us talk about the differences between while(1) and while(0) in C language.
| Parameters | while(1) | while(0) |
| Basics | The while(1) acts as an infinite loop that runs continually until a break statement is explicitly issued. | The while(0) loop means that the condition available to us will always be false. |
| Function | Not just while(1), but every non-zero integer is capable of giving a similar effect like how the while(1) does.Thus, whether it is while(1), while(3), or while(-764), all of these would generate infinite loops only. | It is just the opposite of the while(1) loop. The execution of the code will, thus, never really occur. |
| Uses | It is only advised to use the while(1) loop in the places where the condition always needs to be true. | It is only advised to use the while(0) loop in the places where the condition always needs to be false. |
| Cons | But the usage of while(1) is not practically advisable.It is because this loop is capable of increasing the usage of the CPU and then blocking the actual code.Meaning, we can’t really come out of a while(1) loop unless someone manually closes that particular program. | It doesn’t let a line of code get executed in a program if used accidentally. There is no way out. |
2.4 Difference Between Structure and Array in C?
| Parameter | Structure in C | Array in C |
| Definition | It is a type of data structure in the form of a container that holds variables of different types. | It is a type of data structure that works as a container to hold variables of the very same type. Array does not support variables of multiple data types. |
| Allocation of Memory | In a structure, the memory allocation for the input data doesn’t require being in consecutive memory locations. | The array stores the input data in a memory allocation of contiguous type. It means that the array stores its data in a type of memory model where the memory blocks hold consecutive addresses (it assigns memory blocks consecutively). |
| Accessibility | For a user to access the elements present in a structure, they require the name of that particular element (it is mandatory for retrieval). | On the other hand, any user can easily access the elements by index in an array’s case. |
| Pointer | A structure holds no concept of internal Pointer. | An array, on the other hand, implements Pointer internally. It always points at the very first element present in the array. |
| Instantiation | One can create an object from the structure after a later declaration in its program. | An array does not allow the creation of an object after the declaration. |
| Types of Data Type Variables | A structure includes multiple forms of data-type variables in the form of input. | A user cannot have multiple forms of data-type variables in an array because it supports only the same form of data-type variables. |
| Performance | A structure becomes very slow in performance due to the presence of multiple data-types. The process of searching and accessing elements becomes very slow in these. | The process of searching and accessing elements is much faster in the case of an array due to the absence of multiple data-type variables. It is, thus, better and faster in performance. |
| Syntax | struct sructure_name { element type 1; element type 2; .. }; | type name_of_array [size] |
| Bit Field | You can define a Bit field in a structure. | You cannot define a Bit field in an array. |
| Access | You can access the Structure elements by their names. | You can access the Array elements by their index numbers. |
| Operators | The element accessing operator for a structure is a dot operator “.“ | The element accessing operator and declaration for an array is a square bracket [ ] |
| Size | The various elements in a structure are of different sizes each. | The array contains various elements of the same size. |
| Keyword | We use the keyword “struct” to define a structure. | No keyword is present to declare an array. |
| User-defined | The structure is a user-defined form of data type. | An array isn’t user-defined. It is declared directly. |
2.5 Difference Between Structure and Union in C?
| Parameter | Structure | Union |
| Keyword | A user can deploy the keyword struct to define a Structure. | A user can deploy the keyword union to define a Union. |
| Internal Implementation | The implementation of Structure in C occurs internally- because it contains separate memory locations allotted to every input member. | In the case of a Union, the memory allocation occurs for only one member with the largest size among all the input variables. It shares the same location among all these members/objects. |
| Accessing Members | A user can access individual members at a given time. | A user can access only one member at a given time. |
| Syntax | The Syntax of declaring a Structure in C is: struct [structure name] { type element_1; type element_2; .. } variable_1, …; | The Syntax of declaring a Union in C is: union [union name] { type element_1; type element_2; .. } variable_1, …; |
| Size | A Structure does not have a shared location for all of its members. It makes the size of a Structure to be greater than or equal to the sum of the size of its data members. | A Union does not have a separate location for every member in it. It makes its size equal to the size of the largest member among all the data members. |
| Value Altering | Altering the values of a single member does not affect the other members of a Structure. | When you alter the values of a single member, it affects the values of other members. |
| Storage of Value | In the case of a Structure, there is a specific memory location for every input data member. Thus, it can store multiple values of the various members. | In the case of a Union, there is an allocation of only one shared memory for all the input data members. Thus, it stores one value at a time for all of its members. |
| Initialization | In the case of a Structure, a user can initialize multiple members at the same time. | In the case of a Union, a user can only initiate the first member at a time. |
2.6 Explain What Are The Different Storage Classes In C?
Four types of storage classes are there in c.
1.Auto
2.Register
3.Static
4.Extern or Global
2.7 Explain What Are The Different Qualifiers In C?
- Volatile: A variable should be declared volatile whenever its value could change unexpectedly. In practice, only three types of variables could change:
- Memory-mapped peripheral registers
- Global variables modified by an interrupt service routine
- Global variables within a multi-threaded application
- Constant:
- The addition of a ‘const‘ qualifier indicates that the (relevant part of the) program may not modify the variable.
2.8 What Is Pass By Value And Pass By Reference?
Pass By Value:
- In this method, the value of the variable is passed. Changes made to formal will not affect the actual parameters.
- Different memory locations will be created for both variables.
- Here there will be a temporary variable created in the function stack that does not affect the original variable.
Pass By Reference :
- In Pass by reference, an address of the variable is passed to a function.
- Whatever changes are made to the formal parameter will affect the value of actual parameters(a variable whose address is passed).
- Both formal and actual parameters shared the same memory location.
- it is useful when you are required to return more than 1 value.
2.9 Which statement is faster ++I or i+1?
- ++i instruction uses single machine instruction like INR (Increment Register) to perform the increment.
- For the instruction i+1, it requires to load the value of the variable i and then perform the INR operation on it. Due to the additional load, ++i is faster than the i+1 instruction.
Embedded C Interview Questions for Experienced Engineers
3.1 What do you understand by startup code?
A startup file is a piece of code written in assembly or C language that executes before the main() function of our embedded application. It performs various initialization steps by setting up the hardware of the microcontroller so that the user application can run. Therefore, a startup file always runs before the main() code of our embedded application.
3.2 Functions of Startup file?
Following are the main functions of a startup file:
- Disable all interrupts
- Copying initialized global, global static, and local static variable data from flash to .data section RAM memory of a microcontroller
- Copying uninitialized global, global static, and local static variable data from flash to .bss section of RAM memory and initialize .bss section of RAM to zero.
- Allocate space for the stack and initialize the stack pointer
- It also contains an array of function pointers ( interrupt vector table) that point to various interrupt vector routines such as interrupts and exceptions. The startup file also contains definitions of these interrupt or exception routines such as reset handler, NMI handler, bus fault handler, etc.
- Enable interrupts
- Calls the main function
3.3 What are the differences between process and thread?
Threads differ from traditional multitasking operating-system processes in several ways:
- The processes are typically independent, while threads exist as subsets of a process.
- The processes carry considerably more state information than threads, whereas multiple threads within a process share process state as well as memory and other resources.
- The processes have separate address spaces, whereas threads share their address space.
- The processes interact only through system-provided inter-process communication mechanisms.
- Context switching between threads in the same process typically occurs faster than context switching between processes.
3.4 What is ISR?
For every interrupt, there must be an interrupt service routine (ISR), or interrupt handler. When an interrupt occurs, the microcontroller runs the interrupt service routine. For every interrupt, there is a fixed location in memory that holds the address of its interrupt service routine, ISR. The table of memory locations set aside to hold the addresses of ISRs is called as the Interrupt Vector Table.
3.5 Role of Interrupt Vector Table in Interrupt Processing?
- ARM Cortex-M CPU has two modes of operation such as thread mode and exception. In normal execution, CPU runs in thread mode. But when an interrupt occurs the CPU transfers from thread mode to exception mode. In exception mode, nested interrupt vector controller manages all interrupt and exception requests.
- When an interrupt x occurs, the interrupt request will be sent to NVIC. If NVIC accepts the exception/interrupt request x, the next step of NVIC to find the starting address of the interrupt service routine or exception handler. The starting address of the respective ISR or exception handler is stored inside the interrupt vector table. Then NVIC uses exception number x to calculate the address of the exception by looking up the interrupt vector table and use the content of that memory address (which is an address of the respective exception handler) to execute the exception handler.
- Program counter will be loaded with the address of the exception handler and the CPU starts to execute the exception routine.
- The interrupt processing procedure of ARM cortex-M is quite lengthy. Therefore, we will post a separate article on it.
3.6 Explain What Is Interrupt Latency? How Can We Reduce It?
Interrupt latency is the time required to return from the interrupt service routine after tackling a particular interrupt. We can reduce it by writing smaller ISR routines.
3.7 What are the uses of the Keyword Static?
In the C programming language, static is used with global variables and functions to set their scope to the containing file. In local variables, static is used to store the variable in the statically allocated memory instead of the automatically allocated memory.
Note: In C, the static variables are placed in the BSS or DATA segments. The BSS segment contains the uninitialized data. The DATA segment keeps the initialized data.
3.8 What does “const int x;” mean?
It means the variable is a read-only constant integer.
3.9 Where are constant variables stored in memory?
Depends on your compiler, your system capabilities, your configuration while compiling.
gcc puts read-only constants on the .text section, unless instructed otherwise.
3.10 How can you protect a character pointer by some accidental modification with the pointer address?
Constant character pointer (const char*) prevents the unnecessary modifications with the pointer address in the string.
3.11 Can a variable be volatile and const both?
Yes, there are cases where it can make sense. In summary, a const volatile means that the code cannot change the value of the variable, but something outside of the program can. Some use cases for this include:
- Read-only hardware registers
- Read-only shared memory buffers where one CPU writes and another only reads
3.12 What is a Null pointer?
A Null pointer does not point to any valid memory location. It ensures that no pointer should be used to modify as it is invalid. It is addressed as NULL.
3.13 What is the size of a pointer?
The size of a pointer in C/C++ is not fixed. It depends upon different issues like Operating system, CPU architecture etc. Usually it depends upon the word size of underlying processor for example for a 32 bit computer the pointer size can be 4 bytes for a 64 bit computer the pointer size can be 8 bytes.
3.14 When does a segmentation fault occur?
A segmentation fault or access violation occurs when a program attempts to access a memory location that is not exist, or attempts to access a memory location in a way that is not allowed.
Seg faults are mostly caused by pointers that are:
- Used to being properly initialized.
- Used after the memory they point to has been reallocated or freed.
- Used in an indexed array where the index is outside of the array bounds.
3.15 What Is Difference Between Using A Macro And Inline Function?
An inline function is a normal function that is defined by the inline keyword. An inline function is a short function that is expanded by the compiler. And its arguments are evaluated only once. An inline functions are the short length functions that are automatically made the inline functions without using the inline keyword inside the class.
Syntax of an Inline function:
inline return_type function_name ( parameters )
{
// inline function code
}It is also called preprocessors directive. The macros are defined by the #define keyword. Before the program compilation, the preprocessor examines the program whenever the preprocessor detects the macros then preprocessor replaces the macro by the macro definition.
Syntax of Macro:
#define MACRO_NAME Macro_definition3.16 How can you use a variable in a source file defined in another source file?
If global variables are defined in another file, you can expose them using extern.
For example, if in file2.cpp you have variables declared as follows:
int var1;
int var2;Then in main.cpp you can use the variable using extern:
// define these near the top of your cpp file and then use them wherever you need to
extern int var1;
extern int var2;3.17 Little and Big Endian Mystery?
Little and big endian are two ways of storing multibyte data-types ( int, float, etc). In little endian machines, last byte of binary representation of the multibyte data-type is stored first. On the other hand, in big endian machines, first byte of binary representation of the multibyte data-type is stored first.
Suppose integer is stored as 4 bytes (For those who are using DOS-based compilers such as C++ 3.0, integer is 2 bytes) then a variable x with value 0x01234567 will be stored as following.

3.18 List the 4 levels of testing in Embedded Systems.
The 4 levels of testing are
- Unit testing
- Integration testing
- System testing
- User acceptance testing
3.19 What is multithreading and multiprocessing?
Both Multiprocessing and Multithreading are used to increase the computing power of a system.
Multithreading:
Multithreading is a system in which multiple threads are created of a process for increasing the computing speed of the system. In multithreading, many threads of a process are executed simultaneously and process creation in multithreading is done according to economical.
Multiprocessing:
Multiprocessing is a system that has more than one or two processors. In Multiprocessing, CPUs are added for increasing computing speed of the system. Because of Multiprocessing, There are many processes are executed simultaneously.
3.20 What is Mutex?
Mutex is a mutual exclusion object that synchronizes access to a resource. It is created with a unique name at the start of a program. The mutex locking mechanism ensures only one thread can acquire the mutex and enter the critical section. This thread only releases the mutex when it exits in the critical section.

It is a special type of binary semaphore used for controlling access to the shared resource. It includes a priority inheritance mechanism to avoid extended priority inversion problems. It allows current higher priority tasks to be kept in the blocked state for the shortest time possible. However, priority inheritance does not correct priority inversion but only minimizes its effect.
Example
This is shown with the help of the following example:
wait (mutex);
.....
Critical Section
.....
signal (mutex); 3.21 What is Semaphore?
A semaphore is a signaling mechanism and a thread that is waiting on a semaphore can be signaled by another thread. This is different than a mutex as the mutex can be signaled only by the thread that called the wait function.

A semaphore uses two atomic operations, wait and signal for process synchronization.
The wait operation decrements the value of its argument S, if it is positive. If S is negative or zero, then no operation is performed.
wait(S)
{
while (S<=0);
S--;
}The signal operation increments the value of its argument S.
signal(S)
{
S++;
}3.22 What are the 2 types of Semaphore?
There are two types of semaphores:
- Binary Semaphores: In Binary semaphores, the value of the semaphore variable will be 0 or 1. Initially, the value of semaphore variable is set to 1 and if some process wants to use some resource then the wait() function is called and the value of the semaphore is changed to 0 from 1. The process then uses the resource and when it releases the resource then the signal() function is called and the value of the semaphore variable is increased to 1. If at a particular instant of time, the value of the semaphore variable is 0 and some other process wants to use the same resource then it has to wait for the release of the resource by the previous process. In this way, process synchronization can be achieved.
- Counting Semaphores: In Counting semaphores, firstly, the semaphore variable is initialized with the number of resources available. After that, whenever a process needs some resource, then the wait() function is called and the value of the semaphore variable is decreased by one. The process then uses the resource and after using the resource, the signal() function is called and the value of the semaphore variable is increased by one. So, when the value of the semaphore variable goes to 0 i.e all the resources are taken by the process and there is no resource left to be used, then if some other process wants to use resources then that process has to wait for its turn. In this way, we achieve the process synchronization.
3.23 Is there any difference between Deadlock and Starvation?
- Deadlock occurs when each process holds a resource and wait for other resource held by any other process.
- Starvation is the problem that occurs when high priority processes keep executing and low priority processes get blocked for indefinite time.
3.24 Difference between RS232 and RS485 (RS232 vs RS485)?
RS-232
RS-232 is the simplest of the two interfaces. It is used to connect two devices as illustrated below:
That is, the transmitter of Device 1 is connected to the receiver of Device 2 and vice versa. Both lines are single-ended with a ground reference. The standard specifies a voltage between -3 and -25 V as a logic 1 and a voltage between +3 and +25 V as a logic 0. The cable used to connect Device 1 and Device 2 can be made up of either parallel wires or a twisted pair and should generally not exceed 15 meters.
Most serial devices use a Universal Asynchronous Receiver Transmitter (UART) integrated circuits to implement a communication protocol that transmits portions of data (typically 8 bits) along with a defined set of start-bits, stop-bits, and parity-bits at a specified data rate. The transmitted data is often ASCII characters. Data rates typically range from 4800 to 115.200 baud.

RS-485
While RS-485 and RS-232 have a lot in common regarding the data format, they differ on a very significant parameter: Where RS-232 specifies single-ended connections referenced to ground, RS-485 specifies differential signaling on two lines, called A and B. Up to 32 devices can be connected via the same RS-485 bus, though only one device can “talk” at any given time (half-duplex).
RS-232 AND RS-485 DIFFERENCES

A voltage of -200 mV is specified as a logic 1, while +200 mV is specified as a logic 0. In its nature, the differential format provides common-mode noise cancellation. The differential format along with the lower voltage levels also enable higher data rates and much longer cable lengths than RS-232. Depending on the data rates, cables can be up to 1200 meters long. According to the RS-485 standard, the cables must be twisted pairs.
3.25 What is CAN?
A Controller Area Network (CAN bus) is a robust vehicle bus standard designed to allow microcontrollers and devices to communicate with each other in applications without a host computer. It is a message-based protocol, designed originally for multiplex electrical wiring within automobiles to save on copper, but can also be used in many other contexts
3.26 Why CAN?
- Simple and flexible in Configuration.
- CAN is Message-Based Protocol.
- Message prioritization feature through identifier selection.
- CAN offer Multi-master Communication.
- Error Detection and Fault Confinement feature.
- Retransmission of the corrupted message automatically when the bus is idle.
3.27 Standard CAN vs Extended CAN?
In 1991, Originally Bosch released CAN specification CAN 2.0 for passenger Vehicles which explains 11- bit identifier frame architecture but later on it divided into CAN 2.0(A) which is named as standard CAN be used in passenger cars dealing with 11-bit Identifier while other is CAN2.0(B) which is known as extended CAN be used in heavy vehicles like Buses and Trucks it deals with 29-bit Identifier. So the basic difference in both standard at message Identifier field.
CAN2.0A for Standard Frame Format for Passenger Vehicles
CAN2.0B for Extended Frame Format for Heavy Vehicles
Standard or Classical CAN Frame
The standard frame format is specified in can Specification CAN2.0(A) by Robert Bosch. See below table for frame fields, sub-fields and its role in CAN Frame.Frame Format For Standard CAN

Note : Identifier available in standard CAN is 2048(2^11) but 2032 is available due to some implementation reason.
Extended CAN Frame Format
The extended Frame of CAN is almost similar to the standard frame except for its arbitration field. See below table for frame fields, sub-fields and its role in CAN Frame.Frame Format For Extended CAN

So as you can see Arbitration field in the extended frame format only differ from the standard CAN means extended CAN architecture designed in such a way that standard and extended CAN coexist on the same network.
Note: Available Identifier in Extended CAN is about 500 million (2^29).
3.28 How do CAN bus modules communicate?
CAN bus uses two dedicated wires for communication. The wires are called CAN high and CAN low. When the CAN bus is in idle mode, both lines carry 2.5V. When data bits are being transmitted, the CAN high line goes to 3.75V and the CAN low drops to 1.25V, thereby generating a 2.5V differential between the lines. Since communication relies on a voltage differential between the two bus lines, the CAN bus is NOT sensitive to inductive spikes, electrical fields or other noise. This makes CAN bus a reliable choice for networked communications on mobile equipment.

3.29 Why Can Is Having 120 Ohms At Each End?
An ISO 11898 CAN bus must be terminated. This is done using a resistor of 120 Ohms in each end of the bus. The termination serves two purposes:
- Remove the signal reflections at the end of the bus.
- Ensure the bus gets correct DC levels.


steroid stacks for bulking
References:
https://coolpot.stream/story.php?title=amazon-los-mas-vendidos-mejor-aceleradores-testosterona-de-nutricion-deportiva
steroid cutting cycle
References:
https://rentry.co/kytwwcne
best legal steroid alternative
References:
https://ekademya.com/members/pilotcloud5/activity/177420/
References:
Casino william hill
References:
https://bookmarkfeeds.stream/story.php?title=96c-login-effortless-and-secure-access-to-your-casino-experience
References:
Seminole casino tampa
References:
https://firsturl.de/LUI72PK
%random_anchor_text%
References:
https://output.jsbin.com/leqataragi/
legal performance enhancing drugs bodybuilding
References:
https://bookmarks4.men/story.php?title=guia-completa-sobre-oxandrolona-beneficios-dosis-recomendadas-y-precauciones-a-tener-en-cuenta
is a steroid a protein
References:
https://fancypad.techinc.nl/s/iNDYnJfBZt
References:
Anavar bodybuilding before and after
References:
http://community.srhtech.net/user/redstool69
sustanon deca dianabol cycle
References:
https://krebs-borg-2.mdwrite.net/leanful-avis-2026-bruleur-de-graisses-naturel-efficace-et-durable
References:
Encore casino
References:
https://farmsolutionsja.com/members/deadatom7/activity/21891/
References:
Hard rock casino tampa fl
References:
https://fakenews.win/wiki/WD40_Casino_Review_Evaluation_of_Features_and_Safety
Helpful info. Fortunate me I discovered your
website by accident, and I am stunned why this accident did
not came about in advance! I bookmarked it. https://Rgrealestate.com.mx/agents/douglasthaxton/
References:
Solitaire strategy
References:
https://web.ggather.com/angorablouse41/
References:
Before and after test cyp 500 week and anavar pics
References:
https://www.udrpsearch.com/user/brickelbow97
Die Seriosität steigt natürlich, wenn es sich um ein lizenziertes Casino handelt. Die Seriosität eines Online Casinos hängt davon ab, ob dem Casino eine gültige Glücksspiellizenz der Gemeinsamen Glücksspielbehörde der Länder vorliegt. Einen Bonus bewerten wir aber nicht nur anhand der Höhe des Bonusgeldes oder anhand der Anzahl der Freispiele. Besonders beliebt ist der Willkommensbonus für neue Kunden. Casinos ohne Einsatzlimit verfügen meist nicht über eine deutsche Lizenz – hier ist besondere Vorsicht geboten, was Spielerschutz und Sicherheit betrifft. Insgesamt macht Knightslots einen rundum gelungenen Eindruck. Der Willkommensbonus von 50 € ist zwar nicht der größte, eignet sich aber gut für Einsteiger, die erste Erfahrungen sammeln möchten.
Auch im Jahr 2025 wird es viele neue online Casinos geben. Da die meisten zeitlich begrenzt sind, kann es sein, wenn man sich einige Tage nicht in dem Casino anmeldet, das der Bonus oder die Freispiele verfallen sind. Oft informieren die online Casinos auch per Mail über Bonis oder Freespins. In keinem Spielcasino, Spielothek oder Spielhalle gibt es Bonus Geld oder freies Spielen an den Automaten oder Tischen. Einzig und allein die Spielauswahl auf dem Handy ist etwas geringer als am Computer, Laptop oder dem PC. Fast jedes online Casino hat eine App oder Mobile Version.
References:
https://santcugat-decidim-production.s3.amazonaws.com/casino%20b%C3%BCnde.html
Its like you learn my thoughts! You seem to grasp a lot approximately this, like you wrote the e-book in it or something.
I feel that you just can do with a few percent to drive the message home a little bit, however other
than that, that is wonderful blog. A great read. I will certainly be back. https://Preprod.Catchupbox.com/@alphonsokraus2?page=about
how much hgh to take a day for bodybuilding
References:
https://a-taxi.com.ua/user/taxicello40/
how much hgh for muscle growth
References:
https://aryba.kg/user/hockeysmile99/
hgh bijwerkingen
References:
how long to cycle hgh (https://v.gd/imZAbW)
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks https://Wp.Nootheme.com/jobmonster/dummy2/companies/tonybet-login41/
This is my first time pay a quick visit at here and i am in fact impressed to
read everthing at alone place.
winstrol v steroid
References:
https://yourrecruitmentspecialists.co.uk/employer/dianabol-vs-winstrol-a-scientific-comparison-for-muscle-gains/
what steroids look like
References:
https://pakrozgaar.com/employer/stacking-dianabol-and-winstrol-is-a-dbol-winny-cycle-possible/
trusted online steroid suppliers
References:
https://gitea.chaos-it.pl/ernestinaelkin
term to 100
References:
https://template110.webekspor.com/?p=80
pros of anabolic steroids
References:
http://cgi.members.interq.or.jp/
Greetings from Carolina! I’m bored at work so I decided to browse your blog on my iphone during
lunch break. I really like the info you provide here and can’t
wait to take a look when I get home. I’m amazed at how quick your blog loaded on my cell phone
.. I’m not even using WIFI, just 3G .. Anyhow, very good site! https://Slotsgemnz.Wordpress.com
Saved as a favorite, I love your blog! https://Playamocasinoca.wordpress.com/
Good day I am so excited I found your weblog, I really
found you by accident, while I was searching on Yahoo for something else, Regardless I am
here now and would just like to say many thanks for a fantastic post and
a all round thrilling blog (I also love the theme/design), I don’t
have time to go through it all at the minute but I have bookmarked it and also included your RSS feeds, so when I
have time I will be back to read more, Please do keep
up the great b. https://tonybet4uk.wordpress.com/
By operating within the bypass move or on a free-standing tank, the Desorber-Filter-Unit D10 ensures steady oil
drying and nice filtration, unbiased of machine operation. The desorption process
works independently of viscosity, additives and air content material in the oil.
CJC® Nice Filters are offline oil filtration options with
built-in circulating pumps for off-line set up. The filters are recognized around the globe as extremely efficient purification techniques for applications involving hydraulic oil,
lubrication oil, gear oil, diesel gasoline, quenching oil,
phosphate esters and extra. By investing in our oil filtration methods, you will obtain the lowest
value per kilo of dirt eliminated and vital cost financial savings, with
each short- and long-term advantages. For instance, your
in-line oil filters and parts may have longer lifetimes.
You will avoid lots of the oil-related failures and
breakdowns brought on by contaminated oil.
Please be inspired from our video collection with installation guides, tips
on how to exchange CJC® Filter Inserts, oil situation monitoring and so on. and learn how simple oil upkeep may
be for you with CJC® – your pure resolution for optimum oil upkeep.
Director Ridley Scott solid Curry in the film after watching him in Rocky
Horror, pondering he was ideal to play the position of Darkness.
It took 5 and a half hours to apply the make-up needed for Darkness onto
Curry and on the finish of the day, he would spend an hour
in a shower in order to liquefy the soluble spirit gum.
Aside from one Fangoria interview in 1990, Curry by no means publicly acknowledged his involvement in It until an interview with Moviefone in 2015,
the place he called the position of Pennywise “an exquisite part”.
He rose to prominence as Dr. Frank-N-Furter in the musical movie The Rocky
Horror Picture Present (1975), reprising the function he had
originated in the 1973 London, 1974 L A, and 1975 Broadway musical stage productions of The Rocky Horror Show.
Grant Thornton LLP is a licensed unbiased CPA firm that gives attest services to its shoppers, and Grant Thornton Advisors LLC and its subsidiary entities provide tax and enterprise consulting
companies to their clients. Grant Thornton Advisors LLC and its subsidiary
entities aren’t licensed CPA companies. If you imagine
that a decide has a incapacity affecting his or her efficiency or has violated a quantity
of of the Canons of the Code of Judicial Conduct, it’s acceptable to file a grievance with the CJC.
Please describe as particularly as possible what the choose did or said that causes you to believe
she or he has a disability or has committed misconduct.
Use the “Particular Information” part of the shape to elucidate,
in your own words and with as a lot element as possible, the circumstances that led to your complaint
and the details and evidence that you simply consider exist
to assist your complaint. CJC® Depth Filters have a filtration diploma of three microns absolute and a really
giant dirt-holding capacity, offering maximum safety. Right Here, you’ll uncover a career that provides you
more flexibility, alternative and help to empower your passions.
The identical yr, Curry appeared within the comedy thriller
movie Clue as Wadsworth the butler. A CJC® Offline Oil Filtration system is a kidney loop
answer that reduces your CO₂ footprint. By avoiding expensive oil adjustments and preserving the
oil constantly clean, waste is reduced. CJC® Fantastic Filters are a reliable and an eco-friendly
answer for ensuring the longevity and reliability of your tools.
Curry continued to play the character in London, Los Angeles, and Ny City until 1975.
Grant Thornton Worldwide Restricted (GTIL) and the
member corporations, together with Grant Thornton LLP and
Grant Thornton Advisors LLC, usually are not a worldwide partnership.
GTIL is a non-practicing, worldwide, coordinating
entity organized as a private company limited by guarantee integrated in England and
Wales. Services are delivered by the member companies; GTIL does not present services to clients.
GTIL and its member firms are not brokers of, and don’t obligate, one another
and are not answerable for one another’s acts or omissions.
“Grant Thornton” is the model name beneath
which Grant Thornton LLP and Grant Thornton Advisors LLC and
its subsidiary entities present skilled services.
As a Sergeant, he served as supervisor in the Security Division, Inside Affairs Investigator, Public Data Officer, Legislative
Liaison, and oversaw the Hid Handgun Program.
Sheriff Joseph Roybal started his career with the El Paso County Sheriff’s Office in October 1995.
His early assignments inside the Detention Bureau included serving as a Deputy within the Security Division, member of the
Particular Response Staff, and Court Docket and Transport Deputy
at the El Paso County Courthouse. Please notice that
a judge is not required to recuse himself or herself from a particular matter merely as a result of a celebration concerned in that matter has filed a complaint with
the CJC. If you’ve a disability that stops you from submitting a written grievance, please contact
the CJC’s workplace to debate how this office can finest accommodate your wants.
Make certain that you have got stuffed out the criticism form fully
and accurately.
CJC® Desorber-Filter-Units D10 cut back the water content
material in your oil to below a hundred ppm inside a very quick time.
At the identical time, the built-in fantastic filter minimizes particles and oil ageing merchandise (acids, varnish, sludge).
The D10 unit is right for hydraulic oils, gear oils and lubricating oils – whether or
not primarily based on mineral oil or as an artificial fluid.
Even secure emulsions with a water content material of as
much as 70 % can be dried and processed efficiently.
Individually modifiable because of modularly implementable oil sensors and the quite a few choices from data transmission to automated knowledge interpretation. Offline
oil filtration, or kidney loop oil filtration, extend oil change intervals significantly.
The oil filtration system will clean the oil during operation, eradicating damaging put on particles within the system.
Discover your system and make contact with us, so we will assist you in selecting
an optimum resolution in your best long-term investment ever, through a professional
partnership. On this web page, the Prison Policy Initiative
has curated the entire analysis that we all know of in regards to the conditions of confinement in prisons and jails.
For research on different legal justice topics, see
our Research Library homepage. The El Paso County
Sheriff’s Office was created in 1861, when El Paso County
was formed as one of the 17 counties in the new Colorado Territory.
Sheriff R. Scott Kelley was appointed Sheriff-the first
of 29 men to hold that title over the subsequent 150+ years and laid
the foundation for an Workplace that presently sets the nationwide normal in offering the absolute best service to the residents.
Our 541 sworn and 313 civilian workers are our greatest
asset and ensure our mission is carried out each day. Our imaginative and prescient is
to ensure El Paso County stays the most secure and most enjoyable place to reside and visit within the state of
Colorado.
References:
ipamorelin acetate/sermorelin
At Peptides.org, we highly recommend Limitless Life to researchers who are ready to source HGH peptides for their analysis
studies. Limitless Life has demonstrated an outstanding
dedication to product quality, secure and responsible peptide distribution, and customer service.
In Accordance to available scientific information, CJC-1295 DAC has
been administered effectively in doses ranging between 30-60mcg per kilogram of physique weight per week 12.
Due To This Fact, if you’re trying to enhance your physique composition by way of gaining muscle or losing fats, stacking Sermorelin and Ipamorelin may help you achieve your fitness
goals even quicker. It’s important to spotlight that CJC 1295 isn’t a one-size-fits-all resolution, and its use should be
closely monitored by a healthcare skilled.
Understanding its distinct role in optimizing natural hormonal processes is essential for those contemplating this remedy as a part of their wellness journey
or performance enhancement regimen. CJC 1295 peptide therapy is a promising and distinct approach in the field of anti-aging and hormone optimization. They’re not as stiff, they do not appear to
be as sore, their knee would not harm as a lot. We’ve realized that
we begin with the dose primarily based upon these, like
you mentioned, animal studies, which is conservative, make sure it is secure.
However, in accordance with Mayo Clinic, these changes are because of the pure decline of human progress hormone
(HGH) that comes with age. As the sector of peptide analysis continues to expand, understanding
the differences and potential synergies between these peptides is essential for designing targeted and effective research.
A melanocortin receptor agonist commonly studied for its effects
on sexual health and arousal. As with any medical remedy, it’s crucial to consult with a healthcare skilled earlier than starting Sermorelin remedy.
Sermorelin therapy is often utilized in anti-aging therapies due to its capacity to promote cell regeneration, enhance
pores and skin elasticity, and improve muscle mass.
In Distinction To HGH injections, which entails injecting synthetic HGH immediately into the body, Sermorelin works by stimulating the release of HGH from
the pituitary gland. This natural approach is believed to be safer and extra sustainable
in the long run.
After injecting Ipamorelin, your pituitary gland will
secrete development hormone and this helps each muscle growth and growth.
Ipamorelin is a pentapeptide (i.e. a peptide spanning five amino acids
in length) that mimics the natural launch of the starvation hormone ghrelin and
HGH in the physique. Take step one towards a more healthy, extra vibrant life with informed
peptide therapy. Sermorelin remedy has been correlated with
the enhancement of sleep patterns and an total enchancment in sleep high quality.
Restorative sleep not solely revitalizes the physique but also heightens energy ranges and enhances basic well-being.
However, it’s crucial to emphasize that using CJC 1295 should be beneath the steering of a healthcare professional, as improper dosing or misuse can result in side effects and disrupt
the body’s hormonal balance.
Ipamorelin and CJC1295 are typically administered by way of
subcutaneous injection. These peptides affect the cardiovascular
system by supporting heart well being and rising power
levels. The injection administration aids in the selective
pulse of growth hormone, probably benefiting the heart and
vascular system.
CJC-1295 is a modified synthetic peptide, structurally associated to the endogenously
occurring progress hormone-releasing hormone (GHRH).
It is modified for elevated stability and longer period of motion. Its extended length of action is what makes it stand out compared to different GHRH-analogs.
cjc 1295 ipamorelin tesamorelin and sermorelin 1295 is acknowledged for its extended
half-life, leading to a doubtlessly decreased need for injections compared to Ipamorelin. Conversely,
Ipamorelin is lauded for its capability to stimulate the pure production of development hormone without inflicting important elevations in other hormones similar to cortisol.
Injection website reactions, characterized by symptoms like redness,
swelling, or tenderness on the injection website, are commonly noticed with peptide injections like CJC 1295.
Complications might come up on account of hormonal fluctuations and increased levels of
progress hormone. Water retention is an extra potential aspect impact triggered by the body retaining extra fluids.
Ipamorelin functions as a development hormone secretagogue by emulating the
impact of ghrelin on the pituitary gland, thereby fostering muscle progress and adipose tissue discount.
Furthermore, Ipamorelin is acknowledged for its potential to
elevate athletic efficiency through the enhancement of muscle power and endurance.
Beyond its influence on physical health, this peptide has been observed to assist in weight administration and the regulation of metabolism, thereby contributing to the achievement
of a more healthy body composition. But they’re a sensible, low-risk way to improve progress hormone naturally,
especially as we age and levels drop. Compared to injecting HGH, they don’t shut down your personal production, and they’re extra
sustainable long term. Sermorelin helps steadiness excessive and low HGH ranges within the physique,
which extends its functionality. It binds to pituitary gland receptors, boosting the body’s pure GH production throughout.
This contrasts with Ipamorelin, which has a short
half-life and drastically increases GH levels.
Each peptides play crucial roles in regulating the pulsatile secretion of HGH,
which is crucial for numerous physiological functions corresponding to development, metabolism, and tissue restore.
MK-677 (Ibutamoren) is an oral development hormone secretagogue
(GHS) that mimics the action of ghrelin to stimulate the release of progress hormone
(GH) and insulin-like growth factor-1 (IGF-1). Ipamorelin might be the
higher match if your focus is on fats loss, muscle development,
or faster restoration and particularly if you would like fewer unwanted aspect effects.
Sermorelin works by stimulating your body’s natural growth hormone
production. The earlier than and after adjustments mirror regular positive aspects in sleep,
vitality, fats loss, and muscle tone. With medical supervision and a targeted plan, you presumably can flip small
weekly wins into huge adjustments over six to 12 months.
Understanding the right dosage for Ipamorelin is crucial for
maximizing its benefits—improved development hormone release, better restoration, and
enhanced physique composition—while minimizing unwanted effects.
This guide will stroll you thru everything from what Ipamorelin is and
the means it works, to detailed beginner and superior dosing
charts, administration tips, and safety considerations.
Whether you’re new to peptides or refining
your routine, you’ll discover the data you should dose Ipamorelin confidently and effectively.
Research indicates that Sermorelin helps improve sleep high quality, increase metabolism,
and improve cognitive perform. By optimizing hormone levels,
individuals undergoing Sermorelin therapy could expertise elevated power levels, improved immune perform,
and a more youthful appearance. Scientific research have shown that
Sermorelin remedy can lead to increased muscle mass, reduced physique
fat, improved bone density, and enhanced energy levels.
One of the vital thing advantages of Sermorelin remedy is its ability to optimize Progress Hormone (GH) ranges,
that are essential for numerous bodily capabilities.
By stimulating the pituitary gland to release extra GH, Sermorelin contributes to
elevated muscle development, decreased body
fats, and improved metabolism. At PeptidesPower.com, we’re devoted to offering top-quality peptides, hormone therapies, and wellness dietary supplements to help
your well being, health, and recovery objectives. Sourced from trusted and
reputable peptide sciences, all of our products bear rigorous
testing to ensure the highest levels of purity, efficiency,
and effectiveness.
This oblique method is commonly thought-about safer and
more balanced, allowing your physique to control hormone levels naturally.
In this information, you’ll learn precisely how sermorelin works, what dosage
ranges are perfect for men, girls, and bodybuilders, and tips on how to measure and modify your dose
safely. We’ll additionally cover unwanted effects, schedules, and what to do should you miss a shot — so
you feel assured from day one. By sticking to the really helpful dosing schedule, you can optimize the
benefits of Sermorelin and Ipamorelin on your well being whereas
minimizing any potential unwanted side effects. However, physique weight or
lean body mass didn’t present any vital change.
This peptide mixture can reduce belly fats by way of lipolysis (i.e.
the process of breaking down fats) alongside resistance training and an insulin-controlled
diet.
Sermorelin acts by stimulating the pituitary gland to launch extra growth hormone, which is
essential for various important bodily capabilities.
This peptide therapy involves the injection of synthetic Sermorelin to trigger the production of progress hormone, which declines with age.
Sermorelin, an artificial peptide compound, interacts with the pituitary gland by binding to particular receptors, prompting the discharge of development hormone.
In a research within the Archives of Neurology, adults who got
GHRH therapy had improved cognitive perform after 20 weeks of remedy.
GH treatment didn’t induce an additional enhance in insulin levels throughout an oral glucose tolerance check (OGTT) however
significantly decreased free fatty acid (FFA)
ranges throughout OGTT. We aimed to judge whether weekly administered low dose
of sustained-release rhGH (SR-rhGH) may play a therapeutic function within the therapy of belly obesity.
Most studies have used supraphysiological doses of rhGH, which have been administered
daily or each different day. IGF-1 plays a vital position in cell progress, muscle
restore, and general tissue health.
Our personalised plans include medical guidance, flexible dosing, and doorstep delivery — all
backed by licensed healthcare providers. Although not widespread, some users may experience fatigue,
poor sleep, or irritability after stopping sermorelin abruptly, especially if their body has tailored
to greater HGH levels. Missing one dose of sermorelin isn’t often an enormous deal — however frequent
lapses can disrupt your outcomes and throw
your hormone balance off observe. Since sermorelin depends on consistency to stimulate
regular development hormone production, staying on schedule issues more
than many individuals realize. Sermorelin impacts hormone
levels, and when dosed improperly, it can throw off your mental stability.
This is very common within the early levels of use or when doses
are changed too shortly with out proper monitoring.
This regulation of GH levels performs a vital position in metabolism,
cell repair, muscle development, and total well-being.
Most users report noticeable modifications in sleep high quality, recovery,
and efficiency within 2–4 weeks. Visible physique modifications
(lean mass or fat loss) often occur after 6–8 weeks of
consistent use. Sermorelin is an artificial analog of progress
hormone-releasing hormone (GHRH).
To make positive the receipt of a real product, we strongly
advocate seeking out a reputable provider of ipamorelin. Researchers may seek the guidance of the relevant literature from previous trials to see
how it has been dosed in past studies. This indicates that researchers excited about experimenting with ipamorelin can be well-advised to exclude test topics with pre-existing circumstances corresponding to diabetes and hypertension. Relating To Ipamorelin,
understanding the method to regulate the dosage can make a big difference within the outcomes you obtain. Ensuring the quality and authenticity
of ipamorelin vs sermorelin steroids merchandise
is paramount to safeguarding against counterfeit substances and guaranteeing the desired
results for the users. This mixed approach not only accelerates the advantages of GH therapy but in addition provides a more balanced
and sustained influence on total well-being.
This makes Sermorelin safer, extra pure, and easier to regulate for long-term use.
For long-term customers, a break of 1–2 months after a 3–6
month cycle is commonly recommended. This helps stop
receptor desensitization and retains the pituitary gland responsive.
Sermorelin therapy goals to restore a healthier development hormone rhythm rather than override it.
It stimulates your body’s pure progress hormone manufacturing with
out suppressing testosterone or altering androgen ranges.
That makes it a a lot milder and safer possibility for restoration and efficiency enhancement.
In the world of performance enhancement and anti-aging medicine, peptides
have emerged as one of the effective and focused instruments for development, recovery, and
physique composition. Amongst them, Ipamorelin stands out as a fan favourite —
praised for its ability to stimulate pure progress hormone (GH) launch
without the unwanted facet effects usually seen with different
GH-releasing compounds.
Progress hormone (GH) plays a important position in body composition, mobile repair, metabolism, and wholesome aging.
By stimulating IGF-1 production and protein synthesis,
higher GH ranges can lead to increased muscle energy and reduced fats accumulation. Quite
than injecting artificial HGH, many advanced wellness sufferers
and athletes are turning to peptide therapies that enhance the body’s own GH output.
Three of the preferred progress hormone–releasing peptides are Sermorelin, CJC-1295 (with
and with out DAC), and Ipamorelin.
Seriously, this brief e-book will prevent lots of wasted money and poorly frolicked (not to say
preventing you from potential self-inflicted missteps).
And ensure you get your stack from a dependable vendor, similar to BioLongevity Labs, to keep away from risks and unwanted
unwanted aspect effects. CJC-1295, the GHRH used alongside Ipamorelin, has a for much longer half-life of 6-8 days and this offers some prolonged effects.
As always, it’s important to seek the guidance of your doctor before beginning this peptide mixture.
Research have shown that CJC 1295 might have a more profound impact on physique composition,
selling lean muscle mass development and fat reduction when in comparison with Sermorelin.
One of the key advantages of Ipamorelin is its ability to stimulate the pituitary gland,
resulting in the production of extra development
hormone within the body. This increase in development hormone not solely
aids in muscle progress but additionally helps in reducing fat stores, promoting
a leaner body composition.
A research printed in Peptides Journal demonstrated that the Sermorelin-Ipamorelin mix produced
300% higher IGF-1 ranges than both peptide alone. This
synergy is why most bodybuilders prefer the combination strategy.
Another necessary examine within the American Journal of Physiology showed that Ipamorelin stimulates GH
release without affecting cortisol or prolactin. This selectivity profile makes it safer for long-term
use in comparability with older peptides.
You’ll stroll away with beginner stacks, advanced
combos, safety logic, common stack dosages, and the means to do it
the proper way. From a facet impact standpoint, the peptides could trigger delicate water retention or tingling in some
customers initially, but these effects are sometimes transient.
Correct dosing is crucial – extra isn’t always better, especially with CJC-1295 DAC
which lasts so long (overdoing it might elevate IGF-1 excessively).
A doctor-guided program will begin you at the applicable dose for
your physique size and regulate primarily based in your response.
Prepared to start out your journey toward better hormone levels with Sermorelin or Ipamorelin? Our knowledgeable patient care coordinator will guide you to select the
right selection, explain the method, as nicely
as reply your questions. Really Feel free to ask for extra details or help to make your finest option on your wants.
The administration of the Sermorelin Ipamorelin blend sometimes involves subcutaneous injections,
with precise dosage pointers offered by way of personalised
care and session with healthcare professionals.
Ipamorelin, however, stimulates the manufacturing of IGF-1 (insulin-like development issue 1) in the
liver independently of progress hormone (GH) ranges. Thankfully, utilizing growth hormone-releasing
peptides like Sermorelin and Ipamorelin may help increase
progress hormone and IGF-1 ranges, thereby improving people’s health and vitality.
The utilization of those peptides in a managed and monitored manner under the guidance of healthcare experts
can help people achieve optimal outcomes while minimizing potential dangers or unwanted effects.
Understanding one’s present hormone ranges and cardiovascular
threat components can information the customization of therapy plans to optimize both short-term and long-term
health outcomes.
Any individual looking for any advice on any prescription treatment,
or any disease or situation, is advised to chorus from utilizing this web site and consult their healthcare provider.
Statements regarding merchandise offered on Peptides.org
are the opinions of the individuals making them and aren’t essentially the same as these of
Peptides.org. Sermorelin and ipamorelin are similar in that they each seem to stimulate the body to provide more progress hormone.
In the absence of data from any other human scientific
trials, little else is thought about ipamorelin’s unwanted effects and safety profile.
Injection website reactions are incessantly reported along side this remedy,
manifesting as redness, swelling, or irritation on the injection site.
Complications characterize one other prevalent aspect impact famous by
certain individuals undergoing this remedy. Delicate flu-like signs, inclusive
of fatigue, muscle aches, and low-grade fever, can also manifest.
It is essential to hunt guidance from a healthcare professional
ought to these side effects endure or intensify.
Are you on the lookout for a pure way to boost muscle growth,
aid in weight reduction, and improve total health and wellness?
References:
https://git.17pkmj.com
the effects of steroids on the human body
References:
camtalking.com
legal steroids free trial
References:
https://orailo.com/
bad effects of steroids
References:
https://18let.cz/@florheyer8467
side effects of steroid use in males
References:
karayaz.ru
best stack for weight loss and muscle gain
References:
brandmoshaver.com
does dianabol work
References:
http://www.chenisgod.com
jay cutler before steroids
References:
https://built.molvp.net
deca vs dbol
References:
community.srhtech.net
0ahukewjro_2u–_mahv9fjqihw1ccukq_auidcga|anabolic steroids|acybgnqivwvdk_gu8guso6hssvaojmb0yg:***
References:
schoolido.lu
did arnold use steroids
References:
https://graph.org
definition steroids
References:
https://qa.gozineha.ir/user/chairsword5
anabolic steroids are primarily used in an attempt to
References:
codimd.fiksel.info
anabolic supplement reviews
References:
https://www.google.co.ck/
garcinia cambogia plus free trial
References:
https://iotpractitioner.com/forums/users/cinemabowl1
anabolic steroids benefits
References:
http://www.annunciogratis.net/author/dealschool70
legal steroids for sale usa
References:
https://schoolido.lu/user/cocoapocket1
bodybuilding drug list
References:
tellmy.ru
best prostate supplement on the market
References:
anabolic steroids effects on males, stareanconsulting.com,
anabolic steroid dangers
References:
bostin loyd steroid cycle (nildigitalco.com)
best legal anabolic steroids
References:
Why Are Anabolic Steroids Bad
weightlifting supplement reviews
References:
best cutting steroid stack, quickdate.click,
steroids for massive muscle gain
References:
strongest legal steroid (https://heartbeatdigital.cn)
science of steroids
References:
roid Meaning, Git.ides.club,
best natural anabolic supplement
References:
can prednisone help build muscle (git.chilidoginteractive.com)
oral trenbolone for sale
References:
steroid use body Building (https://rapid.tube/)
how do people take steroids
References:
What Do Steroids Do For You [https://Soundcashmusic.Com/]
effects of steriods
References:
uk anabolics, demo.playtubescript.com,
ipamorelin dosage for bodybuilding
References:
is ipamorelin Worth it (gratisafhalen.be)
It’s great that you are getting thoughts from this post as
well as from our dialogue made at this place. https://krabiproperty.com/author/mellissax4461/
My brother recommended I might like this web site. He was entirely right.
This post truly made my day. You cann’t imagine just how much time I had
spent for this info! Thanks! https://Sushantassociates.com/employer/euro-girls-escort
ipamorelin legal status 2025
References:
How Much Cjc-1295 Ipamorelin Should I Take (Git.Ellinger.Eu)
cjc 1295 ipamorelin dac or no dac
References:
what is the doseage for 5mg sermorelin 5mg ipamorelin
Peculiar article, just what I wanted to find.
how often to take cjc 1295 ipamorelin
References:
Cjc 1295 Ipamorelin Before And After Pics
tesamorelin vs ipamorelin vs cjc-1295
References:
cjc 1295 Ipamorelin heart attack
peptide cjc 1295 ipamorelin
References:
Cjc-1295 ipamorelin cost Per month
I’mnot that much of a onine reader to be
honest but your sites really nice, keep it up! I’ll go ahead and bookmark your website to come back down the road.
Many thanks https://anotepad.com/note/read/amxc2xs7
Hey I know thiis is off topicc but I was
wondering if yyou knew of any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for a plug-in like this for quite some
time and waas hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates. https://Married-Bramble-848.Notion.site/Login-To-Azurslot-262247007a3e8000a1a3ef05f876d7e6
Hi there are using WordPress for your site platform?
I’m new to the blog world butt I’m trying to get started and set up my own. Do you need any html coding knowledge to make your own blog?
Any help would be really appreciated! https://Zenwriting.net/fou9plvhra
Unquestionbly believe that which you stated. Your favorite justification appeared to be on the intewrnet the easiest thing to be aware of.
I say to you, I certainly get iked while people consider worries that they plainly do
nnot know about. You managed to hit the nail upon the top and also
defined out the whole thing without having side effect , people can take
a signal. Will prrobably be back to gett more.
Thanks https://Zenwriting.net/4enc6hyz2j
Great blog! Do you have any hints for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for a paid option? There arre so many options out ther that I’m totally confused ..
Any suggestions? Many thanks! https://Telegra.ph/Check-Out-The-Slot-Selection-09-02
I am in fact grateful to the holder of this web
site who has shared this wonderful paragraph at
at this place. https://Groups.google.com/g/azurslotcom/c/uGip7Z_xu0o
I’ve read a ffew good stuff here. Definitely price bookmarkking for revisiting.
I wonder how a lot attempt you puut to make the sort of excelleent informative site. https://Www.03247.com.ua/list/530661
I do nnot even know how I stopped up right here, however I believed this publish wass great.
I do not know who you’re but definityely you are going to a famous
blogger iff yyou aren’t already. Cheers! https://onlinemarketings2025.wordpress.com/
Excellent web site you have here.. It’s difficult to find excellent writing
lioe yours these days. I seriously appreciate individuals like you!
Take care!! https://bookofdead34.wordpress.com/
gnc muscle building pills
References:
negative side effects Of steroids (hafrikplay.com)
how many iu of hgh does the body produce
References:
4 Iu hgh per day results (https://relink.pt/)
dianabol anavar cycle
References:
valley.md
intermittent fasting and creatine
References:
can u take creatine while fasting; https://sciencewiki.science/,
hgh bodybuilding dosierung
References:
hgh cutting cycle (http://www.Giveawayoftheday.com)
what is a high roller in gambling
References:
what is considered a high roller at a casino (karayaz.ru)
what is a high roller in gambling
References:
game of spades (hedgedoc.k8s.Eonerc.rwth-aachen.de)
Excellent pieces. Keep writing such kind of info on your site.
Im really impressed by it.
Hi there, You have performed an excellent job.
I will certainly digg it and in my view recommend to my friends.
I am confident they’ll be benefited from this website.
References:
synthol vs steroids (Aspiring-Cuckoo-qzfgs5.mystrikingly.com)
is dbol legal in the us
References:
Best Steroid For Lean Muscle And Fat Loss (https://Charmed-Serial.Online/User/Humordry76/)
legit steroids sites
References:
is creatine like steroids (gratisafhalen.be)
Es schließt sich additionally die Frage an, wie hoch die Wachstumshormonproduktion bei einem gesunden Menschen sein sollte. Zu den Aufgaben des Hormons Somatostatin zählt auch die Unterdrückung unserer Wachstumshormonproduktion. Untersuchungsergebnisse zeigen, dass die tägliche Einnahme von 3 bis 6 g der Aminosäure L-Arginin die Ausschüttung dieses Hormons unterdrücken kann. Dies führt möglicherweise zu einer Unterstützung der körpereigenen Wachstumshormonproduktion.
Regelmäßige ärztliche Untersuchungen und eine sorgfältige Überwachung sind hierbei unerlässlich. Die Wirkungen von hGH werden größtenteils durch den Insulin-like Progress Factor 1 (IGF-1) vermittelt, der als zentraler Mediator fungiert. Die Bestimmung von IGF-1 gibt Hinweise auf die durchschnittliche hGH-Sekretion über einen längeren Zeitraum. Dies macht IGF-1 zu einem wichtigen Marker in der Diagnostik und Überwachung der hGH-Wirkung im Körper.
Denn für diese Personengruppe liegen klinische Studien vor, die die Wirkung bestätigen. Das liegt darin begründet, dass mit zunehmendem Alter die Melatoninproduktion der Zirbeldrüse abnimmt, was häufiger mit Schlafproblemen verbunden ist – und mithilfe von Melatonin therapiert werden kann. Allerdings wird die Einnahme nur für die kurzzeitige Therapie von Schlafstörungen empfohlen. Zudem darf ein rezeptpflichtiges Melatoninmedikament auch nur dann verschrieben werden, wenn keine anderen ersichtlichen Gründe für das Auftreten einer Schlafstörung vorliegen. Der Artikel handelt von Adam, einem Mann, der Testosteron-Enantat nimmt, um Muskeln aufzubauen.
Es ist zu beachten, dass die Ergebnisse bei der überwiegenden Mehrheit der HGH-Anwender nicht sofort und auf natürliche Weise sichtbar sind. HGH kann einige ziemlich unglaubliche Dinge bewirken, aber es wird als eine langfristige Aufgabe angesehen. Während es immer ein oder zwei gibt, die in kurzer Zeit große Fortschritte machen können, müssen die meisten Menschen es über einen längeren Zeitraum nutzen, um dies zu ermöglichen. Bevor du Gebrauch von melatoninhaltigen Präparaten machst, empfiehlt es sich grundsätzlich immer, erstmal seine Schlafrituale zu verbessern, um dadurch für einen besseren Schlaf zu sorgen. Rezeptpflichtige Melatoninpräparate hingegen enthalten 2 mg des Hormons, sind aber ausschließlich Personen ab 55 Jahren vorbehalten.
Bei Patienten mit Verdacht auf Akromegalie sollteIGF-1 im Serum gemessen werden. Die IGF-1-Spiegel sind in der Regel deutlich erhöht (um das 3- bis 10-Fache), und da die IGF-1-Spiegel nicht wie die GH-Spiegel schwanken, sind sie der einfachste Weg, um eine GH- Hypersekretion zu beurteilen. Einige Frauen mit Akromegalie leiden unter Galaktorrhö, die häufig im Zusammenhang mit einer Hyperprolaktinämie zu sehen ist. Allerdings kann eine Galaktorrhö auch durch exzessive GH-Spiegel ausgelöst werden, da auch GH alleine die Laktation stimulieren kann. Eine verminderte Gonadotropin-Ausschüttung findet man im Zusammenhang mit GH-sezernierenden Tumoren.
Dazu zählt unter anderem die Sauerkirsche, da sie eine natürliche Quelle an Melatonin darstellt und dazu noch jede Menge Vitamin C aufweist. Vor allem die sogenannte Montmorency-Sauerkirsche läuft mit 13,5 Nanogramm Melatonin anderen Lebensmitteln den Rang ab. Der Verzehr einer Handvoll dieser Kirschen vorm Schlafengehen soll zusätzlich müde machen und dabei helfen, besser ein- und durchzuschlafen. Auch die Verwendung elektronischer Geräte reicht schon aus, um die Melatoninproduktion zu hemmen. Denn Tablet, TV, Smartphone oder Laptop strahlen blaues Licht ab, das das Schlafhormon zurückhält und dafür sorgt, dass wir nicht müde werden.
Diese Hormone wirken sich ebenfalls positiv auf deinen Muskelaufbau aus. Mit einer gesunden Ernährung, ausreichend Schlaf und wenig Stress ist es möglich, der altersbedingten Reduzierung der Wachstumshormone entgegenzuwirken. Eine direkte Aufnahme ist aufgrund drohender Nebenwirkungen und der ungewissen Herkunft nicht empfehlenswert. Es kann durchaus sein, dass deine Hirnanhangdrüse nicht ausreichend HGH produziert, um deinen Muskelaufbau und die Fettverbrennung zu fördern.
Es besteht aus über one hundred ninety Aminosäuren und erfüllt eine wichtige Funktion im menschlichen Körper, da es für das Wachstum von Organen und Geweben (sowohl Weichgewebe als auch Knorpel und Knochen) verantwortlich ist. Somatotropin beeinflusst auch die Proteinsynthese und stimuliert die Zellteilung, worüber wir weiter unten mehr schreiben. Sofern kein signifikanter dauerhafter Mangel an Wachstumshormonen vorliegt, besteht aus medizinischer Sicht kein Grund dazu, auf eine entsprechende Therapie zu pochen. Um deinen HGH-Spiegel additionally dennoch optimieren zu können, ohne dabei auf die hierzulande illegale Hilfe der Chemie zurückgreifen zu müssen, stehen dir prinzipiell zwei Wege zur Auswahl. Erstens, hartes Krafttraining und zweitens, eine ausreichende Menge an Schlaf.
References:
https://timbertransit.com/employer/hgh-36-ie-somatropin-kaufen-preis-579-euro-in-deutschland-dosierung-und-kurs/
Er folgt damit auf Dr. Patrick Frey, der über elf Jahre hinweg für verschiedene Einrichtungen der Waldbreitbacher
Marienhaus Unternehmensgruppe tätig warfare und aus persönlichen Gründen ausgeschieden ist.
Die Anwendung “vdek-Kliniklotse”steht in Ihrem Land derzeit nicht zur Verfügung.Bitte prüfen Sie, ob es eine regionale Different gibt oder kontaktieren Sie uns für weitere Informationen. Nach meinen monatelangen Schmerzen im Knie struggle
ich zur Spiegelung und Glättung des Meniskus in der Klinik.
Ich hatte nach dem Eingriff absolut keine Schmerzen und bin nun schmerzfrei.
Das ganze Group ist absolut nett, kompetent und ich würde
jederzeit wieder kommen. Die Inhalte und Dienste auf sanego
dienen der persönlichen Information und dem Austausch von Erfahrungen. Eine individuelle
ärztliche Beratung oder eine Fernbehandlung finden nicht statt.
Nach größeren Operationen im Bauchraum
oder gynäkologischen Operationen sowie in der Geburtshilfe bieten wir, um eine
effektive Schmerztherapie zu erreichen, die thorakale bzw.
Die interdisziplinäre Intensivstation verfügt über 6 Intensivbehandlungsbetten mit 2 Beatmungsplätzen, wovon je three Betten der internistischen und
der operativen Intensivmedizin zugeordnet sind. Nach größeren Bauchoperationen oder unfallchirurgischen Operationen intensivmedizinisch überwacht und behandelt.
Auch gehört die differenzierte Beatmungstherapie bei Störungen des
Gasaustausches der Lungen und die Behandlung von Schockzuständen oder septischen Patienten zu den Aufgaben der Intensivtherapie.
Die operative Intensivmedizin wird von der Anästhesieabteilung verantwortlich geleitet.
Die Versorgung von Wunden erfolgt durch die Chirurgen der Fachabteilung Allgemeine
Chirurgie. Bei Wunden, die bereits bei der stationären Aufnahme bestehen, erfolgt eine erste Versorgung in der Notaufnahme.
Wenn aufgrund des Krankheitsbildes oder des Krankheitsverlaufs eine Intensivbehandlung erforderlich
ist, erfolgt die Aufnahme oder Verlegung des Patienten auf die
Intensivstation. Die interdisziplinäre Intensivstation verfügt über
6 Intensivbehandlungsbetten mit four Beatmungsplätzen.
Um eine möglichst effektive, nebenwirkungsarme und der Operation angepasste Schmerztherapie zu erreichen, bieten wir
neben der Patientenkontrollierten intravenösen Schmerztherapie (PCIA) auch
mehrere ultraschallgestützte Regionalanästhesieverfahren an. Zur postoperativen Schmerztherapie kann hierbei
an ausgewählte Nerven ein dünner Katheter buying steroids online in usa
Lokalanästhesie platziert werden, über den die Nerven kontinuierlich mit einem modernen Lokalanästhetikum umspült werden.
Rechtzeitig vor Beginn der Narkose wird den Kindern ein angstlösendes und beruhigendes Medikament in Kind
eines gut schmeckenden Safts verabreicht. Vor der
Narkoseeinleitung wird eine Venenverweilkanüle am Handrücken, am Unterarm oder an der Ellenbeuge platziert.
Das Legen der Kanüle wird von den Kindern intestine akzeptiert.
Wenn Sie uns per E-Mail, Telefon oder Telefax kontaktieren, wird Ihre Anfrage inklusive aller daraus hervorgehenden personenbezogenen Daten (Name, Anfrage) zum Zwecke der Bearbeitung Ihres Anliegens bei uns gespeichert und
verarbeitet. Diese Daten geben wir nicht ohne
Ihre Einwilligung weiter. Die Verarbeitung dieser Daten erfolgt auf Grundlage von Art.
6 Abs. B DSGVO, sofern Ihre Anfrage mit der Erfüllung eines Vertrags zusammenhängt oder zur Durchführung vorvertraglicher
Maßnahmen erforderlich ist. In allen übrigen Fällen beruht
die Verarbeitung auf unserem berechtigten Interesse an der effektiven Bearbeitung der an uns gerichteten Anfragen (Art.
6 Abs. 1 lit. f DSGVO) oder auf Ihrer Einwilligung
(Art. 6 Abs. 1 lit. a DSGVO) sofern diese abgefragt wurde.
Daten, die zu anderen Zwecken bei uns gespeichert wurden, bleiben hiervon unberührt.
Nach Ihrer Austragung aus der Newsletterverteilerliste wird Ihre E-Mail-Adresse bei uns bzw.
In einer Blacklist gespeichert, sofern dies zur Verhinderung künftiger Mailings erforderlich ist.
Die Daten aus der Blacklist werden nur für diesen Zweck verwendet und nicht mit anderen Daten zusammengeführt.
Dies dient sowohl Ihrem Interesse als auch unserem Interesse an der Einhaltung der gesetzlichen Vorgaben beim Versand von Newslettern (berechtigtes Interesse im Sinne des Art.
6 Abs. 1 lit. f DSGVO). Die Speicherung in der Blacklist ist zeitlich nicht befristet.
Das Insolvenzverfahren für das Heilig-Geist-Hospital (HGH) Bingen ist abgeschlossen, das Amtsgericht hat das Verfahren zum 1.
Wenige Tage zuvor gab der Geschäftsführer Martin Mueller im Kreistag
einen kurzen Überblick über den Stand der Übernahme
der Geschäftstätigkeit des bisherigen Betreibers, der Marienhaus
GmbH.
Unsere Menüstruktur unterstützt eine dritte Ebene, wobei darauf
geachtet werden sollte, dass diese nicht die beiden letzten Menüpunkte betrifft, um ein klares und zugängliches Navigationslayout zu gewährleisten. Notfälle behandeln wir jederzeit mit
Voranmeldung. “Die Grundversorgung am Standort Bingen zu erhalten, ist nicht nur für uns als Stadt wichtig, sondern auch für den Landkreis”,
betont der Binger Oberbürgermeister Thomas Feser (CDU). Die Wege
wären sonst für die Menschen zu weit, wenn sie krank sind.
Ihre Auswahl können Sie jederzeit über den Hyperlink “Datenschutz-Einstellungen” im
Footer ändern. Wir sind ein fashionable ausgestattetes Krankenhaus der Grund- und Regelversorgung und verfügen über 173 Planbetten.
Wenn die Datenverarbeitung auf Grundlage von Artwork. 6 Abs.
E oder f DSGVO erfolgt, haben Sie jederzeit das Recht, aus Gründen, die
sich aus ihrer besonderen Scenario ergeben,
gegen die Verarbeitung Ihrer personenbezogenen Daten Widerspruch einzulegen; dies gilt auch für ein auf diese Bestimmungen gestütztes Profiling.
Die jeweilige Rechtsgrundlage, auf denen eine Verarbeitung beruht, entnehmen sie dieser Datenschutzerklärung.
Wenn Sie unsere Web Site betreten, wird eine Verbindung zu
den Servern von Usercentrics hergestellt, um Ihre Einwilligungen und sonstigen Erklärungen zur Cookie-Nutzung einzuholen. Anschließend speichert Usercentrics ein Cookie in Ihrem Browser, um Ihnen die erteilten Einwilligungen bzw.
Die so erfassten Daten werden gespeichert, bis Sie uns zur Löschung auffordern, den Usercentrics-Cookie selbst
löschen oder der Zweck für die Datenspeicherung entfällt.
Zwingende gesetzliche Aufbewahrungspflichten bleiben unberührt.
Im Marienhaus Heilig-Geist-Hospital ist seit Oktober 2016 eine Weaning-Einheit
etabliert. Ein interdisziplinäres und spezialisiertes Staff
verfolgt hier das Ziel, beatmungspflichtige Patienten sicher und qualitativ hochwertig vom Beatmungsgerät zu entwöhnen und sie in ein normales
Leben zurückzuführen. Dieses medizinische
Angebot ist auf eine regionale wie überregionale Patientenversorgung ausgelegt.
Genannten Stationen statt gefunden hat.Persönlich würde
ich unter den jetzigen Bedingungen jederzeit eine dieser bd.
Stationen als Affected Person besuchen und natürlich im Verwandten wie Bekanntenkreis weiter empfehlen. Der
Nutzung von im Rahmen der Impressumspflicht veröffentlichten Kontaktdaten zur Übersendung von nicht ausdrücklich angeforderter Werbung und Informationsmaterialien wird
hiermit widersprochen. Die Betreiber der Seiten behalten sich ausdrücklich rechtliche Schritte im Falle der
unverlangten Zusendung von Werbeinformationen, etwa durch Spam-E-Mails, vor.
classification of steroids
References:
https://careers.mycareconcierge.com/companies/wachstumshormon-hgh-and-peptide-kaufen-sie-legale-hgh-in-deutschland
winaday casino
References:
bellagio casino las vegas (guardian.ge)
Your style is unique in comparison to other folks I’ve read stuff
from. Thank you for posting when you have the opportunity, Guess I’ll just book mark this site.
fat burning steroid cycle
References:
guardian.ge
define steriods
References:
joyeriasvanessa.com
california indian casinos
References:
perth crown casino (https://www.cartergroupland.com/articles/georgia-hunting-season-2022-2023)
download casino games
References:
tulalip casino
most popular steroids for bodybuilding
References:
http://www.belkataherkhani.ir
mobile casino pay by phone bill
References:
dramanews168.com
70918248
References:
steroid transformation before and after; https://newsstroy.kharkiv.ua,
70918248
References:
training on steroids (Lurlene)
70918248
References:
the effects Of steroids on the Human body – https://www.trefpuntstan.be,
70918248
References:
effects of prolonged steroid use on the human Body; trefpuntstan.be,
70918248
References:
what are the advantages and disadvantages of common names (Myles)
70918248
References:
anabolic steroids prescription (https://www.kentturktv.com/)
70918248
References:
alternatives to steroids (talukadapoli.com)
70918248
References:
natural anabolic steroids (https://www.trefpuntstan.be/ontmoet-deel/deel-je-verhaal-detail-pagina/2024/08/12/stan-informeert-nieuwe-regels-voor-vergoeding-bewindvoering)
Excellent post! We will be linking to this particularly great article on our
website. Keep up the good writing.
Women typically require decrease dosages, ranging from 5-20 mg per day, to minimize the chance of virilization (development of
male characteristics) and different unwanted effects.
It is usually thought of one of many more female-friendly anabolic steroids
because of its decrease androgenic properties and reduced danger of virilization compared to different choices.
Flex Lewis, a distinguished bodybuilder and multiple-time
Mr. Olympia winner in the 212 division, has brazenly shared his constructive experiences with
Anavar. His advocacy extends past personal usage, as he emphasizes the significance of obtaining Anavar from reliable sources for protected and efficient outcomes.
It is much safer and simpler to choose out different choices when you wish to boost your athletic
efficiency, retain your muscle mass or simply increase your power ranges.
Anavar is a popular selection for many bodybuilders as a outcome of it’s an efficient
approach to build muscle and cut fat. If you’re a bodybuilder, the recommended dosage of Anavar is 25-50mg per
day. Oxandrolone is a prescription-only medicine that is used to treat quite lots of medical circumstances,
corresponding to muscle wasting and osteoporosis.
It is necessary to notice that Oxandrolone is not an alternative selection to Anavar
and may solely be used under the steering of a healthcare professional.
Nonetheless, it’s important to make use of caution when utilizing any steroid,
as they are often harmful if not used properly. Always comply with the recommended dosage and
consult with a healthcare skilled earlier than use.
Nevertheless, some customers have reported gains of 1-3 kilos inside the first two weeks, relying on their workout
depth and food plan. In addition to muscle and energy enhancements, Anavar has been reported to increase bone density and aid in recovery.
These elements contribute to its recognition among athletes on the
lookout for a competitive edge. In addition, this versatile
steroid has shown promising leads to girls and youngsters coping with osteoporosis, because
it aids in promoting bone density. Due to its mild nature, Anavar has been a most well-liked choice for medical functions as it poses fewer risks when in comparison with more potent steroids.
Where can i buy anavar tablets’ve noticed some variations within the tablet colors, starting from white
capsules. It’s not steroids, so bear in mind to remain consistent together with your
coaching and diet for the most effective results.
Each supply for purchasing Anavar comes with its set of benefits and downsides, and weighing these elements is essential when making an informed decision. When contemplating the acquisition of Anavar, prospective buyers face the selection between online and offline sources.
Every supply has its unique characteristics, advantages, and potential
pitfalls. Empower Pharmacy is the nation’s largest, most superior 503A compounding pharmacy and 503B outsourcing facility.
Our mission is to provide entry to the best compound treatment solutions for sufferers, practitioners, and pharmacies.
Adverse reactions span endocrine, hepatic, metabolic, and dermatologic domains.
Clinically consequential interactions middle on hepatic enzyme
modulation and additive physiologic results.
Nevertheless, with Anavar’s fat-burning effects and
muscle positive aspects being retained post-cycle, there may
be not an excellent want for most people to utilize Anavar all year spherical.
This is due to them being fat-soluble compounds, thus causing the steroid to dissolve when taken with dietary fats.
Subsequently, Anavar and other anabolic steroids ought to be
taken on an empty abdomen for optimal results. High doses of Anavar might cause some flushing to
the face or body, inflicting users’ pores and skin to look purple.
This is an indication of elevated body temperature and potentially elevated
blood stress.
Choosing a trusted supplier ensures you’re getting a protected,
genuine product that delivers the promised outcomes. When implementing the aforementioned cycle,
it is essential to frequently monitor ALT and AST liver enzymes, as
each compounds are C-17 alpha-alkylated. Nevertheless, masculinization is frequent if a feminine increases the Winstrol dose or extends this cycle beyond six weeks.
Nitrogen is a critical component of proteins, and sustaining
a constructive nitrogen stability is significant for muscle growth.
By enhancing nitrogen retention, Anavar creates an surroundings conducive to muscle progress and preservation. The Anavar market is competitive, and counterfeit merchandise pose a serious
threat to your health and wallet. In 2024, it’s important to select suppliers who prioritize quality,
transparency, and buyer satisfaction. Testosterone is an FDA-approved
medication (2), which means that its unwanted effects may be manageable when taken under the
steering of a professional physician. Researchers have described testosterone-replacement therapy as “safe” within the context of treating hypogonadism (3).
In addition to strength positive aspects, Anavar has been linked to increased endurance and sooner recovery
occasions, making it a well-liked selection amongst athletes seeking to enhance their bodily talents.
Another notable good factor about Anavar is its capability to help with fats loss and enhance body composition. This is achieved via its capability to
boost lipolysis, the method of breaking down fat molecules in the body.
Users may discover a decrease in body fat and an increase in lean muscle mass when following an Anavar cycle.
In combination with a well-balanced food regimen and train regimen, Anavar might
help individuals obtain a extra outlined and toned physique.
Anavar is thought for its capability to promote muscle progress
and development of lean muscle mass. It works by growing protein synthesis and nitrogen retention, that are essential for muscle
development.
This might help you higher improve your endurance when figuring out, helping you gain muscle sooner.
Medical Review BoardAll Ignite Healthwise, LLC training is reviewed
by a team that includes physicians, nurses, superior practitioners, registered dieticians, and different healthcare
professionals. Anavar is an artificial anabolic steroid derived from dihydrotestosterone (DHT).
The best on-line pharmacies in Ukraine also supply perfumes, skin care products and gift units.
Respected suppliers usually have certifications or accreditations that validate
their legitimacy.
Customers might expertise features of 1-3 kilos inside the
first couple of weeks depending on their
exercise plan and the intensity of their cycle.
This makes Anavar an attractive choice for those
looking to build lean muscle mass without gaining extra fats.
Nevertheless, it’s necessary to note that the choice
to make use of any anabolic steroid, together with Anavar, must be made in session with a qualified healthcare professional.
Anabolic steroid use carries potential dangers, and medical supervision is
essential to monitor for unwanted effects, guarantee appropriate dosages, and handle any health issues.
Anavar Oxandrolone is known for its capacity
to promote lean muscle growth while concurrently lowering body fat.
It works by increasing protein synthesis and enhancing nitrogen retention, resulting
in improved muscle progress, enhanced recovery, and increased
strength. Some individuals take legal dietary supplements
that have certain steroid hormones additionally made by the
human body.
Hello i am kavin, its my first occasion to commenting
anywhere, when i read this article i thought i could also create comment due to this good post.
My page :: Michael Kors Schuhe
Even so, it’s at all times a smart move to seek the assistance of with your physician in case you have any underlying health points before you start taking them.
IGF-1 instructs your cells to utilize their glucose reserves for gas as an alternative of turning them into fat.
This action keeps weight acquire at bay and leads to a decrease in physique
fats by halting the formation of latest fats stores.
The first and only once-weekly therapy for grownup development hormone deficiency (AGHD).
The most common remedy used for injections is a substance often known as Somatropin. HGH can accelerate
healing within the body, allowing for quicker recovery
following intense exercises. Weightlifting workouts designed to reinforce
muscle mass cause microscopic tears within the muscle tissue,
which indicators them to restore and rebuild. Supplementing with HGH can facilitate
quicker muscle recovery, ensuring you’re pumping iron again with minimal downtime.
HGH supplements can set off lipolysis, your body’s own mechanism for burning fat.
This motion aids in weight reduction, enabling your physique to soften away
extra fat, even when you’re slumbering.
The growth hormone is a chemical called somatotropin,
which is often produced inside the brain. If there may be too little of this chemical occurring naturally, then it can be injected into the physique so as to stimulate progress.
Private progress hormone remedy is an ongoing process, starting with a session and a series of
checks at our clinic.
As we grow older, most of us start to notice that shedding
these further pounds is much more durable to do. This is primarily
because of the position that HGH plays in weight reduction, and after the
age of 30, your HGH levels begin to decline. The catch is
that supplement manufacturers aren’t required to obtain FDA approval before launching their merchandise.
This means they have the freedom to incorporate virtually any ingredient into
their formulation, regardless of its efficacy. Sadly,
some firms exploit this liberty to churn out substandard, ineffective HGH dietary supplements with hefty
value tags. As A Outcome Of the spray is absorbed instantly into the bloodstream, it makes for a much-more potent
and environment friendly supply methodology.
If you were a jock in highschool or school, you’re more probably to wince at the
memory of your coach barking “no ache, no gain” to spur
you on. Today, athletes who use unlawful performance-enhancing medication risk the pain of disqualification without
proof of achieve. Whether Or Not you have questions on which peptide is best for you or need steerage on tips on how
to use our merchandise, we are here to help.
Due to the excessive frequency of injections, it is advisable for the athlete to change injection websites regularly.
In Any Other Case, the pores and skin is more prone to be covered with bumps accompanied
by burning pain. Novo Nordisk is a pacesetter within the growth hormone market, with greater than 25 years of experience.
By taking any one of these high-quality HGH supplements, you’ll really feel younger, stronger, hornier, extra energetic, and just plain higher.
In addition, it enhances the movement of amino acids by way of cell membranes and in addition increases the rate at which
these cells convert these molecules into proteins. Clearly,
you possibly can see that this may quantity to an anabolic (muscle building) effect in the human body.
Human Development Hormone additionally has the ability to trigger cells to decrease
the conventional fee at which they utilize carbohydrates,
and concurrently increase the rate at which they use fat.
We provide lab-tested high quality, offer Next-Day UK Delivery choices, secure fee amenities (Card & Crypto), and ensure trackable, discreet
delivery. Advance your scientific studies with confidence
by choosing Evolution LAB UK. Human Progress Hormone (HGH),
also called Somatropin, is a peptide hormone naturally
produced by the pituitary gland. The recombinant type utilized
in laboratory analysis is a protein consisting of 191 amino acids, similar to the
primary type of endogenous human GH.
In 1513, the Spanish explorer Juan Ponce de Len arrived in Florida to search
for the fountain of youth. If he got any profit from his
quest, it was due to the train concerned within the search.
If you can get this hormone via an exterior supply, it is
possible for you to to get an excellent assistance with muscle building.
Incorporating a development hormone supplement into your
routine could further help in preserving the elasticity and color of your skin as you
grow older. The function of growth hormone extends to varied facets of your physical health.
Opting for the perfect HGH supplements can offer you a substantial enhancement in your GH ranges, resulting in a quantity of benefits for your general health and
vitality. The price ticket is a key consideration when reviewing human development hormone
drugs. A number of producers demand a hefty charge for their HGH dietary
supplements, whereas others could sell their merchandise at suspiciously low cost costs.
However GH recipients experienced a excessive fee of
unwanted aspect effects, including fluid retention, joint ache, breast enlargement,
and carpal tunnel syndrome. The studies had been too quick to detect
any change within the danger of most cancers, however other analysis suggests an elevated risk of most cancers generally and prostate
most cancers in particular. HGH must be used beneath medical supervision to ensure protected and effective outcomes.
WordNovo Nordisk is a highly revered Danish pharmaceutical large with operations around the globe.
The firm specializes in HGH medicines and is recognized as an trade
standard-bearer. Its HGH injection pens consistently receive high praise for their
ease of use and durability. Due to its investigational status it has by no means been marketed for use in people.
References:
lamh
Every weekend i used to pay a visit this web page, for the reason that i want enjoyment, since this this web page conations in fact fastidious funny data too.
He hails from a time when Dbol utilization was
legal and customarily condoned, mirroring the situation we see today.
Its profound influence on the human body extends
previous the normal positive aspects tied with muscle building,
resulting in radical evolutionary enhancements. The choice to incorporate Dbol in your
health routine may bring about noticeable modifications not only in your physique but in addition your performance throughout workouts.
The transformation you witness might depart you astounded and thriving for more.
Whereas Anavar is poisonous to the liver5, as we’d count on with an oral steroid, its
hepatotoxicity level is minimal in contrast with many other steroids,
making this a super choice for beginners. And
with an excellent PCT plan, you’ll save your gains and defend your body while striving for a greater and stronger
version of your self. These are dietary supplements that can help you get Dianabol-like outcomes without any unwanted effects.
They are formulated with the assistance of
natural ingredients and don’t even require a PCT.
By stacking Dianabol with Testosterone of Deca, you can acquire
as a lot as 10 lbs of further muscle mass. In your subsequent cycle, you’ll have the ability to stack Dianabol with other steroids including testosterone or Deca Durabolin, notably for
bulking. Dianabol is hepatotoxic and having alcohol on it increases the chances of
liver damage.
To maximize the benefits of Dianabol, it’s essential to follow a well-designed workout routine and
maintain a balanced diet. Moreover, understanding the beneficial dosage and contemplating potential unwanted facet effects is crucial to stop adverse well being penalties.
It’s crucial for people considering using Dianabol
to weigh these unwanted effects towards the potential benefits and consult a medical
professional earlier than starting any cycle.
Typically, a Dbol cycle’s impression doesn’t merely
finish with impressive muscle gain. The power surge and heightened workout
endurance are equally exceptional transformations usually skilled.
The critiques from seasoned customers and fitness fanatics make clear how this potent anabolic steroid can probably enhance your fitness journey.
Before you announce your new beast title, it’s essential to note that your pure testosterone
production will diminish. Have Interaction in some intense PCT instantly after your Dbol cycle to
claw back this loss. The faster you recover your T production, the less chance you’ll have
of losing the muscle mass you’ve gained.
This property means it can intensify the speed at which your body builds proteins,
your muscles’ main element. By enhancing protein synthesis, Anadrol could augment muscle
growth and development extra rapidly than regular. As far as the relaxation of the article, the article is a “guide” as nicely, for many who are interested in studying about some of what I discuss in this article, anabolic steroids youtube.
Many steroids users, blame Dianabol to be causing back pumps after just 2-3 weeks of cycling
in a average dosage of 30mg every day. But as quickly as my cycle was by way of and I Might stopped taking
it, I realised it wasn’t working at all. Cease using them for the majority of your
cycle, methandienone bodybuilding. It’s hard to think about having to cease using steroids and
the opposite issues you’ve been informed, but that’s exactly what occurred
to me. At the time I determined this was one of
the best pct for dianabol and test cycle forum
strategy for myself, but I’ve since changed my mind…If I Would
just stopped having the steroid and continued to cycle, I Might still get back pain after 3-5 months.
They won’t be turning into the Hulk (nor would most girls want
to), but the elevated definition is a certainty, and with muscle changing fats weight,
any physique weight put on shall be lean muscle. One
of the larger dangers of oral steroids is how they can stress the liver, probably causing liver injury or poisonous hepatitis36.
Anavar has a modification to its chemical structure, often known as
17-a-alkylation modification, which permits us to use this steroid orally.
However in comparability with injectable steroids,
oral steroids will take longer to clear from the liver, and that’s the
place the possible threat lies for liver stress or liver injury.
These long-term side effects are much extra likely to come back
about from some other extra powerful steroids you might be stacking Anavar with rather than from Anavar
itself.
Newbies start with as a lot as 50mg daily, and essentially
the most skilled users can often take up to 100mg every day – however
such a excessive dose isn’t recommended for the novice.
Anavar’s results of helping you sculpt a lean, onerous physique
may be extra delicate. In an 8-week cycle, you’ll have the ability to anticipate to see noticeable constructive
modifications inside the first one to 2 weeks, and naturally, the higher your exercise and food regimen program, the
higher and sooner results you will notice.
Even although Anavar is what we consider to be a milder steroid in comparability with most
others, it’s nonetheless an anabolic steroid. Anavar is a prohibited substance in any nation that has
made the use, possession, manufacture, and sale of anabolic steroids illegal – including the Usa, Australia, and plenty
of European countries. Surprising water retention is another occasional unfavorable comment
users make about Anavar – however these persons are almost certainly victims of purchasing counterfeit Anavar.
All steroids include some negatives, but Anavar is on the lower finish of the scale in relation to
unwanted effects and dangers. Most of those will solely be of concern if you’re utilizing doses which are too excessive or utilizing the drug for longer than beneficial intervals.
Certain, all of us need the outcomes, however lots of guys nonetheless won’t take the plunge
into truly using a steroid like Anavar. Females
naturally produce small quantities of testosterone,
but when using steroids, this powerful androgen can shortly bring
about a complete host of undesirable unwanted facet effects
for females. There are not many steroids that
females can use with out experiencing extreme unwanted facet effects that principally contain the development of various masculine physical traits.
This outcomes from providing the body with significantly higher quantities of male androgen hormones like testosterone and DHT than would in any other case be produced.
Symptoms may be widespread and serious and might embrace fatigue,
depression, low libido, loss of muscle, and fat achieve, to call only a few.
A normal PCT cycle will usually not restore testosterone levels following Trenbolone
use, and longer-term TRT can be required. I suggest
testosterone cruising for four months following this cycle, maintaining in thoughts there’s no
assure of T levels returning entirely again to normal after using Tren.
Il s’agit tout d’abord de changer certaines habitudes
de vie, et en particulier vos habitudes alimentaires.
Il est bon de rappeler que les conséquences peuvent varier d’une personne à l’autre et que certaines personnes peuvent ne pas présenter de
conséquences malgré un taux de testostérone trop bas. Il est donc necessary de consulter un médecin pour évaluer les niveaux d’hormones et pour mettre en place un traitement approprié si
nécessaire. Testo-Max favorise l’augmentation naturelle des niveaux de testostérone.
Il contient des ingrédients tels que l’acide D-aspartique, le magnésium, le zinc, et les vitamines D, B6, K1, qui sont reconnus
pour stimuler la manufacturing de testostérone par l’organisme.
Testo-Max vous promet des gains musculaires significatifs,
d’améliorer vos performances physiques, et de faciliter la récupération sportive.
Testogen est le meilleur booster de testostérone par voie orale, le #1 sur le marché.
C’est celui que j’utilise quand je réalise une treatment et que je recommande à mes
clients. Les sites qui promettent de la testostérone en accès libre
jouent souvent sur l’ambiguïté. Certains vendent des
produits non autorisés en France, ou font passer des agents actifs sous d’autres appellations.
Les logos de pharmacies et mentions légales
ne garantissent pas une traçabilité réelle. Vous l’étalez sur les épaules, les
bras testosterone ou acheter le ventre, et la testostérone traverse la peau petit à petit.
Utilisé depuis des siècles dans les médecines traditionnelles, il est aujourd’hui
reconnu pour son impression positif sur la testostérone libre, la libido et la vitalité globale.
La racine de maca, quant à elle, est traditionnellement utilisée pour soutenir la libido, renforcer la vitalité et
améliorer la résistance au stress, avec un effet world
sur l’énergie physique et mentale. Nous tenons aussi à souligner que les boosters de testostérone peuvent provoquer
une carence en fer. Vérifier les témoignages et les avis est
une excellente façon de se renseigner sur la qualité d’un produit.
Pour faciliter votre sélection, nous vous donnons des critères de choix
indispensables pour vous procurer le booster de testostérone qui vous conviendra le mieux.
Tout pratiquant de musculation recherche ses effets, c’est la raison pour laquelle,
vous ne devez pas négligez cet facet.
En raison de la variabilité des résultats d’analyse entre les différents
laboratoires, tous les dosages de testostérone doivent être effectués par le même laboratoire pour un sujet donné.
En conclusion, la réglementation de la testostérone touche différents aspects de la société, du sport professionnel aux
enjeux médicaux légaux et aux politiques d’entreprise.
Chaque secteur doit naviguer avec prudence dans ce cadre législatif complexe pour garantir la conformité et protéger les
droits des individus concernés. Les lois varient d’un pays à l’autre concernant la prescription et
la distribution de la testostérone, souvent classée comme une substance
contrôlée en raison de son potentiel d’abus.
En effet, les résultats du stéroïde diminuant après 6 à 8 semaines… Son effet
anabolisant est moins marqué. Afin d’aider à protéger l’environnement ne jetez pas les patchs usagés
dans les toilettes, ni dans un système d’élimination de déchets liquides, ni même dans une poubelle.
Une fois tous les patchs utilisés, rapporter la boîte à votre pharmacien.
Comme vous pouvez le voir, les suppléments boosters de testostérone
contiennent des ingrédients dont les bénéfices sont scientifiquement prouvés, ce
qui garantit leur efficacité. Généralement, le gel est appliqué sur une peau sèche sur l’épaule,
l’abdomen ou le bras après le bain. Les patients sont invités à couvrir le website d’application avec des
vêtements pendant au moins 2 heures après l’application afin d’éviter de transférer le gel à d’autres personnes par contact.
Ne pas appliquer Testogel sur les organes génitaux (verge et scrotum),
car la forte teneur en alcool peut provoquer une irritation locale.
Après avoir ouvert le sachet, vider tout son contenu dans la paume de la major et l’appliquez
immédiatement sur la peau. Après avoir étalé le gel, veuillez
vous laver les mains soigneusement à l’eau et au savon. Nous ne sommes autorisés à remettre
cet article que sur ordonnance (loi suisse sur les produits thérapeutiques).
Les études de fertilité chez les rongeurs et les
primates ont montré que le traitement par la testostérone est vulnerable de
diminuer la fertilité par suppression de la spermatogenèse proportionnellement à
la dose. La testostérone s’est révélée non mutagène in vitro selon le modèle des mutations réverses (test d’Ames) ou des cellules ovariennes de hamster.
Et il se trouve à un prix relativement réduit en comparaison des résultats
qu’il vous permet d’atteindre. Tous les ingrédients contenus dans TestoGen sont naturels
et ont fait l’objet d’études scientifiques. C’est pourquoi nous vous présentons les three boosters de testostérone qui sont actuellement les plus efficaces.
En effet, quand vous faites votre choix de complément alimentaire, restez vigilants sur ce que certains fabricants peuvent vous proposer.
Il est préférable de se tourner vers des produits qui ont été testé scientifiquement.
Autrement, rien ne vous garantit que le produit aura un quelconque effet sur votre manufacturing de testostérone.
70918248
References:
none (Mssales.nl)
70918248
References:
none
70918248
References:
none (1proff.ru)
70918248
References:
none – courtiersolaire.fr
–
70918248
References:
what do anabolic steroids do to your body; Salvador,
70918248
References:
do steroids make your penis shrink (tailandiatours.com)
Nevertheless, it could possibly also trigger muscle cramps, particularly in the legs
and palms. Taking Clenbuterol earlier than a exercise can also
assist improve your metabolic price, resulting in increased fats burning.
By growing the quantity of energy your body uses during exercise,
Clenbuterol might help you obtain your weight loss goals faster.
These attainable benefits of mixing supplements are grounded in pharmacological ideas.
Nonetheless, they’re contingent on appropriate dosages and cycles to stop opposed reactions or tolerance
growth. Subsequently, it could be very important consult with a healthcare professional before engaging in any complement stacking routine.
Crazybulk in indiaWhile clenbuterol could additionally be efficient at promoting weight loss and increasing athletic
efficiency, it is essential to be aware of the potential unwanted side effects.
When you’re taking Clenbuterol for an extended interval, your body turns
into accustomed to its results, which makes the beta-2 receptors in your body less responsive.
This powerful fats burner makes use of cutting-edge
ingredients to assist burn fats shortly and efficiently, with out sacrificing muscle mass.
With Clenbutrol, you’ll find a way to rest assured that your
exercises are working towards giving you the body of your dreams, without putting your health at
risk, in distinction to Clenbuterol.
Clenbuterol has a stimulating effect on beta-2 adrenergic receptors, which can affect
satiety ranges in humans. Consequently, our patients have reported decreased hunger throughout the day, regardless
of burning extra energy. This impact can indirectly assist
with further fat loss because of users being more likely to eat in a calorie deficit.
High vitality levels from clenbuterol can (indirectly)
help to burn extra fats because of workouts changing into more intense.
For example, users may perform cardiovascular exercise
on a stationary bike for quarter-hour; however, on clenbuterol, individuals
may find a way to prolong the period to 20+ minutes.
When it involves using Clenbuterol for weight loss or efficiency enhancement, one of the frequent questions is how a lot Clen to take.
The answer to this question is decided by several components, including your gender, weight, and total health.
In this article, we’ll explore the beneficial dosages
for Clenbuterol and supply some tips on tips on how to use it safely and effectively.
Nevertheless, bodybuilders or anyone taking clenbuterol for
weight loss functions may take 6–8 drugs per day (120–160 mcg).
Such dosages are nicely past the therapeutic vary utilized in medicine; subsequently, more severe unwanted side effects are to be expected.
In 2005, the CDC reported 26 cases of clenbuterol poisoning among heroin customers.
They have been hospitalized with symptoms such as rapid heart rate, palpitations, hypokalemia, chest ache, and agitation. Most were saved
within the hospital for 5 days the place they received intravenous fluids, potassium, and drugs to slow down the heart.
The really helpful dosage of clenbuterol for bodybuilders is typically
20 to 40mcg per day, with some athletes going up to 120mcg per day.
However, you will need to begin with a low dosage and progressively
improve to avoid potential side effects similar to
tremors and elevated heart rate. This preservation of muscle
mass is crucial for sustaining strength and performance levels while on a calorie deficit.
Athletes and bodybuilders typically flip to clenbuterol
as a performance-enhancing drug as a result of its capability
to boost endurance and stamina.
Cheale Villa the founder, CEO and Visionary Rabbit, of Visible Caffeine,
a branding and design company, zuma 3d regras do jogo. Taking Part In defense
stud poker technique options include a loyalty packages we ve nearly the software
program platform, jogo da roleta do bitcoin explicado.
This online casino has a few of the best options, we are
going to evaluate this on line casino on the options out there and supply in depth information, zuma 3d
rodadas grátis. You must additionally ensure
that you by no means make a bet more than 10 using the
free chips to comply with the T Cs. In addition, you should solely play
on slot machines, Real-Series Video Slots, keno, scratch cards, or on board video games, zuma
3d slot on-line cassino free of charge. Para isso, devera completar toda a cartela ate
o sorteio da 30 bola., zuma 3d rodadas grátis.
The right dosage may help you achieve your desired outcomes while minimizing the risk of adverse effects.
Clenbuterol can have a number of unwanted aspect effects, together with tremors,
insomnia, complications, and elevated heart rate.
It is important to drink plenty of water when taking Clenbuterol to avoid dehydration. If you expertise any of these unwanted
effects, it is important to cease taking Clenbuterol and consult your doctor.
It may help to extend the body’s metabolic rate, which implies you burn extra energy all through the day.
It additionally helps to increase the body’s core temperature, which leads to an increase in power
expenditure. Clenbuterol can even help to suppress appetite, which can be helpful when making an attempt to shed
weight.
Including clen to your reduce would enhance this by about
220 energy, which might assist you to lose no more than a half of a pound of fats
per week without altering your food plan or exercise.
You’ll find a few of their components in different weight reduction products.
When making an attempt the totally different Clenbuterol cycle Dosage
(jbhnews.com) options, it is a good
suggestion to begin out with clen alone to discover out what works
greatest for you. If you find this dose too low, attempt 1/10 of a cc
each day and double it every 5 days till you reach 80 mcg or a hundred
and twenty mcg. a hundred and twenty mcg is often the maximum
for girls, and a lot of attain their targets with a maximum of eighty mcg.
Om nodvendig kan spilleautomaten Sizzling Rod Racers lastes ned til enhver b?
/casino-bitcoin-online-no-canada-casino-bitcoin-para-o-reino-unido/ You can get up
to 3000 with Ignition On Line Casino s newest 300 welcome bonus when you deposit with crypto.
This supply comes with a low 25x wagering requirement, zuma 3d slot on-line cassino free of charge.
70918248
References:
steroids for bodybuilders (zelfrijdendetaxirotterdam.nl)
Nevertheless, Anadrol and other steroids may cause will increase in visceral fat (6).
This is not the fat you can pinch around your abdomen but as an alternative is positioned internally and wraps round your organs.
It is abundantly obvious from reading the quite a few Energy Life Protein critiques on the internet that users reaped
a number of benefits from the supplement. Many clients gushed about how simple it was to develop bigger, stronger muscles—just sip a delectable shake!
Sam Kramer is a senior diet coordinator & writer who additionally works as a dietitian. The best steroid stack for
energy should embrace Testosterone, Anavar, Trenbolone, and
Dianabol.
Anavar is reported as having a quite delicate impact, when in comparability with other anabolic steroids.
And it’s an excellent bodybuilding steroids for
Sale (hegyvideksport.hu)
supplement for beginner customers who want to optimize
strength, endurance, body composition and constructing muscle.
Overall, authorized steroids are a protected and efficient way
to obtain your health goals with out resorting to illegal and
dangerous anabolic steroids.
As with other OTC dietary supplements, look out for extra elements
that may trigger allergic reactions or long-term health results.
Nevertheless, it doesn’t result within the muscle-building claims this drug’s marketing copy would
possibly lead you to imagine. It’s a naturally occurring substance found in foods like fish and meat.
Some athletes may seem to get an edge from performance-enhancing drugs.
Side effects of creatine can embody gaining weight and cramps
within the stomach or muscle tissue. Some
people try to get extra nutrients from products referred to
as supplements.
D-Bal makes use of a triple-action formula that promotes
most muscle development, strength, and performance. D-Bal works
by boosting protein synthesis, which is the method that helps
restore and build muscles after intense exercises.
By extending this course of, D-Bal allows for elevated muscle improvement and
energy. D-Bal from CrazyBulk is a authorized complement
that is called the closest thing to steroids
for bodybuilding. It is manufactured in a FDA-approved facility to
ensure high quality and security of the product.
For those who wish to obtain outstanding
muscular growth and energy, D-Bal is the best choice.
Thus, gynecomastia and water retention (bloating) are less prone to occur
with the addition of Proviron. Dianabol and testosterone can be
stacked collectively for enhanced results compared to taking either compound
alone. Nonetheless, the diploma of estrogen and androgen-related unwanted facet effects shall be extra extreme.
One Other good thing about Deca Durabolin is that it’s healthier for
the liver. Nandrolone isn’t C-17 alpha-alkylated
(Dianabol is), so ALT and AST levels typically remain steady
in our testing. We have seen ladies avoid virilization side effects when taking Dianabol
in low doses; nevertheless, with trenbolone, masculinization is more
prone to occur.
As it actually works by dampening down your immune system, taking prednisone additionally means that you could be
be at larger threat of getting infections. Oral corticosteroids, corresponding to prednisone, impact your entire body,
and side effects, ranging from mild to severe, aren’t uncommon.
It also has specific unwanted side effects that your healthcare provider may suggest you
combat by restricting your food regimen.
Ultimately, steroids may cause mania, delusions, and violent aggression,
or “roid rage.” Corticosteroids are common steroid drugs that scale back irritation and dampen the
activity of your immune system. They’re lab-made to work like cortisol, a hormone made by
your adrenal glands. Androstenedione, also referred to as andro, is
a hormone everyone’s body makes. The physique turns andro into
the hormone testosterone and a form of the hormone estrogen.
Nevertheless, these are pricey steroids and infrequently counterfeited; thus,
injectable testosterone is the popular alternative for many of our patients.
Oral steroids may also cause testosterone suppression just like injectable steroids, doubtlessly inflicting hypogonadism in males.
The Drug Enforcement Administration (DEA) classifies AAS as Schedule III drugs.
Just possessing them illegally (not prescribed to you
by a doctor) can end result in up to a 12 months in prison and a fantastic of no much less
than $1,000 for a first-time offense. Planning and recording your
exercises and personal fitness targets with an app
is usually a fast, straightforward method to make
sure you’re staying on track.
It’s a useful ingredient used for hundreds of years for enhancing
libido and supporting weight-reduction plan and weight.
Plus, TestoPrime could store some energy for the the rest of the day, making you
fresh and energized after your exercise. Interestingly,
the brand provides a lifetime assure on all TestoPrime supplements purchased
directly from their official website.
Not Like anabolic steroids, Testo-Max is created from
natural ingredients corresponding to Nettle Leaf extract and Fenugreek,(7) which work collectively to spice up your physique’s pure testosterone manufacturing system.
DecaDuro is a legal steroid supplement that has proven to be highly effective
in gaining lean muscle mass and enhancing bodily energy.
It is an all-natural formula that’s backed by scientific analysis
and is safe to use.
The excellent news is that Testol one hundred forty is a pure, protected,
and legal different to Testolone, which means no negative unwanted effects.
General, D-Bal MAX was a incredible product that packed
a punch and helped me build some serious muscle, and I would
advocate this product to anybody who desires to realize muscle fast.
D-Bal Max is a natural alternative to Dianabol,
formulated to provide the identical energy and measurement positive aspects without any unwanted side effects.
Second place on my listing of the best authorized steroids goes to D-Bal
Max. The key ingredient in Suma Root is “ecdysterone,” a naturally occurring steroid
hormone that enhances athletic performance. It also increases ranges of free testosterone, boosting your power
and efficiency. While there are a bunch of good authorized steroids on the market, D-Bal is probably the most
highly effective and my absolute favorite.
With a variety of products, including PCT options, oral and injectable steroids, Maxtreme Pharma is the trusted choice for bodybuilders and athletes across Australia.
Almost something you could want for a steroid cycle, Alpha Pharma produces it,
oral steroids, injectable steroids, PCT products and extra.
Not many people ever talk about the use of anabolic steroids in traditional medication.
But nearly all of these substances were designed to deal with certain medical situations earlier than anything.
Earlier Than they have been changed with more expensive drugs that trigger more unwanted effects, anabolics have been the top treatment for all kinds of
various well being problems. We will contact you as quickly as attainable to verify your order particulars and
offer varied fee methods to finalize your order.
Anavar can produce some mild androgenic effects
in men, and hair loss can be one of these issues for males who have a genetic predisposition to baldness.
From beginners and intermediates to sports activities professionals, each men and women will profit from the desired dietary enhancements out there to
them from any of these branded producers. You should purchase specific sports substances in our
online store from anyplace within the UK. Our
customer support consultant will be there to help you when you are buying with us.
As Quickly As you could have created an account with us, shopping for your subsequent batch of steroids might be even easier.
You just should log into your account, add the items into your cart and make the cost.
Some of the most well-liked chopping steroids for sale available within the market include Anavar, Winstrol, Trenbolone,
and Masteron. These compounds enhance muscle definition, protect lean muscle mass, and promote a optimistic caloric deficit.
They additionally enhance protein synthesis and
nitrogen retention to forestall muscle catabolism. Moreover,
they reduce water retention and improve energy ranges for more intense training sessions.
As you probably can see, estimating a easy lack of fat
in pounds is just about inconceivable. If you’re already
very lean and are just attempting to shred these previous few stubborn kilos, you will be shedding less than someone doing their first cutting cycle.
The mixture of fats loss and lack of subcutaneous water will provide you with that lean look.
Holding on to it after the cycle presents a larger problem than achieving your
shredded physique in the course of the cycle, and that is something you should
plan for.
However you’ll be able to’t be using steroids safely
in case you have no idea that you take them. The TGA is desperately attempting to fight it, however the variety of manufacturers getting in on the action continues to develop.
Our online anabolic retailer makes a speciality of delivering steroids
throughout the US. Very little Oxandrolone is produced for human medical use
nowadays, so there’s hardly any provide
of pharma-grade products. That means it won’t be cheap if yow will discover some (and
ensure it’s respectable and genuine). There are a nice quantity of dangers to long-term well
being, some of Which describes A consequence of steriod abuse?
– litoralgarve.pt, we might
not discover till much later in life. I’m not keen to take that danger anymore, and that’s
how I got here throughout what I imagine is the number one legal substitute for
Anavar – Anvarol.
Anavar, also identified as Oxandrolone, exerts its
effects within the body via a quantity of mechanisms.
One of its main actions is its anabolic impact, which enhances protein synthesis.
By selling the production of proteins within muscle cells,
Anavar facilitates muscle progress and restoration. Sure, one of many huge benefits of
HGH is that ladies can use it without the virilization that
comes with utilizing anabolic steroids. Women will get comparable advantages from HGH to males, but females will often take a decrease dose.
They will concentrate on bettering muscle tone, fat loss, and HGH’s anti-aging effects that may improve the appearance
of pores and skin and hair.
As noted above, medicine injected by way of an injection immediately enter the bloodstream, which permits the body to decrease
toxic results on the liver. ● PREFERRED BY SPORTSPEOPLE The oral type is often chosen by fighters, swimmers, and athletes since few people want to get involved with injections, and the outcome could be fairly respectable.
The detection interval for doping exams is considerably shorter than that of their injectable counterparts.
We are a group of sports activities fanatics working
onerous to offer you a flawless expertise when buying steroids in the
USA. Our buyer requests predominantly come from New
York, Florida, Texas, California, and Michigan.
Furthermore, as a outcome of trenbolone is a potent fats burner (5), the
scales could not mirror the amount of dimension users acquire.
Dianabol continues to be believed to be
the staple bulking steroid in professional bodybuilder stacks at present, 5 many years later.
Step on the human development hormone gas, fireplace up muscle progress and burn via fat stores.
MK-677 has many additional advantages that can enhance your restoration and healing wants.
Two SARMs and a SERM could make up a easy but very potent advanced bulking cycle.
LGD-3303 is taken into account by many to be THE most potent
SARM for bulking. However you should think about the possible additional optimistic advantages and unwanted effects
you’ll get (if any). Stacking means you’re additionally
introducing a new set of unwanted facet
effects, plus amplifying any negatives that every compound shares16.
Another frequent strategy is to stack a dry
SARM with one that promotes fats loss.
The time frames differ, but lots of the merchandise are described as producing
noticeable outcomes inside weeks. For instance, users of Loopy
Bulk Bulking Stack reportedly feel results within days.
I’ve had purchasers break through plateaus they’ve been stuck at for years.
We’re speaking about adding 50 kilos to their
bench press or a hundred kilos to their squat in a matter
of weeks. It’s like watching years of progress unfold in a fraction of the time.
In my years of teaching, all males, with out exception, struggle with
the consequences of declining testosterone.
Vitamin D3, magnesium aspartate, zinc, D-aspartic acid, and black pepper fruit
extract are some of the powerful elements included on this method.
It’s beneficial to take Epitech once within the morning and as quickly as at evening with a meal.
It is particularly efficient when stacked with Big Vitamin Annihilate or Arachidone.
In different words, synthetic steroids essentially trick your body into considering that
they’re testosterone. Once the steroid molecules are in place, they activate the androgen receptors.
Earlier Than committing to one, we had been thinking about finding out what different folks felt
about various manufacturers and supplements. As A Outcome Of of this, we compiled a protracted record
of corporations and targeted on those with the Best
alternative to steroids (megadownload.net)
overall rankings and essentially the most optimistic feedback on their steroid pills.
It is reassuring to learn that the businesses and merchandise
described above have obtained overwhelmingly constructive comments from a significant number of consultants
working in the wellness trade.
This means you’ll use fast-acting compounds – either orals or short-ester injectables.
Normal steroid cycles are often the begin line for model new users however are additionally a staple in the strategy of skilled bodybuilders.
The outcomes achieved over a 10–12-week normal cycle can be fantastic (provided you work onerous within the gym).
It’s additionally not an amazing length of time to decide to utilizing
steroids. Anavar, for instance, is a favorite among feminine bodybuilders
for its capacity to advertise lean muscle progress with minimal unwanted effects.
It’s perfect for ladies who need to enhance strength and definition whereas maintaining a sleek physique.
Whereas injectable steroids are known for their effectiveness in delivering testosterone rapidly and immediately into the bloodstream,
they arrive with their own set of challenges. Beginner steroid stacks embody quite lots of anabolic steroids to realize most results.
Anabolic steroids stimulate protein synthesis, and
beginners can acquire lean muscle sooner than by coaching and diet alone.
Biking steroids refers to taking them for a sure interval with a post-cycle break.
This avoids developing tolerance within the physique
and reduces side effects. In bodybuilding,
this ensures constant improvement and upkeep of your hormonal well being.
D-Bal enhances protein development, nitrogen retention,
and red blood cell formation, leading to overdeveloped
muscle building.
Whereas no supplement can exchange the fundamentals of coaching onerous and eating well, they
will make the method extra environment friendly and effective when used correctly.
From protein powders and creatine to extra advanced
muscle-building stacks, every part highlights what to consider before adding
a product to your routine. An individual’s use of a steroid
or combination of steroids is alleged to be in a steroid cycle.
Cycles are normally structured over weeks to optimize outcomes while managing unwanted effects.
Proper biking is essential for anyone looking to build mass and keep away from problems.
Nonetheless, these stats apply to novices, and thus skilled customers will acquire
less than this. The downside with testosterone pictures is that
they’re not quite as friendly to your physique as
naturally produced testosterone. Examine this Trenbolone evaluation to study
more about how to use it to get most benefits and keep away from
side effects. Its components embrace Tribulus Terrestris, soy protein isolate,
whey protein focus, Shilajit Concentrate, and acetate L-carnitine.
As Dianabol comes with harmful side effects and it’s not authorized to
use with no prescription, you could need to swap to a authorized various
like D-Bal from Crazy Bulk.
It delivers pure muscle and uncooked energy whereas getting rid of undesirable fat.
It leaves you with a hard, ripped, and toned physique, ready to face the bodily challenges
ahead. By putting your metabolism into overdrive, your physique is ready to use your saved fats for vitality.
These embody being jittery, shaking palms, feeling wired, and
having insomnia.
This is as a result of of them being cost-effective,
not painful, and never requiring overly frequent injections (every 4-5 days).
Customers might need to wait slightly longer for them to kick in;
nevertheless, this form of testosterone is usually comfy and enjoyable for novices
to take. Propionate may look like cheap; however, it is
dosed at solely a hundred mg/ml, whereas different types
of testosterone are commonly dosed at round 250
mg/ml.
Getting caught with unlawful steroids can lead
to serious consequences. These sources embody underground labs and overseas sellers.
Steroids are managed substances in many elements of the world.
In some nations, steroids are solely obtainable by prescription. Possession with no prescription can result in authorized hassle.
Although no anabolic steroid is 100% protected, some are categorized as important medicines by main health organizations.
Due to Deca Durabolin’s low androgenicity, users can expertise less nitric oxide manufacturing, which is crucial for optimal blood move.
Bodybuilders who take anabolic steroids to attempt to improve muscle mass and enhance athletic performance can expertise a spread of symptoms.
In some cases, males would possibly start to grow
breasts as a end result of a rise in estrogen ranges.
Many bodybuilders use steroids to recuperate faster from
workouts. Steroids are an artificial form of testosterone, a sex hormone naturally produced by men and women alike.
Taking steroids will increase testosterone ranges, causing effects like elevated muscle mass and energy.
Anabolic steroids embody the hormone testosterone and related medication.
They hid their bodies or prevented certain social situations.
In MD hiding a body are described as a half of the symptomatology (Pope et al., 1997) to not experience anxiety.
Our view, however, leans towards that ladies are concealing their bodies as a
outcome of concern of being uncovered for criminal activity somewhat
than concern of being judged for his or her appearance.
When anabolic steroids are taken with meals, absorption is inhibited.
Post-cycle therapy (PCT) aids within the recovery of the HPTA (hypothalamic-pituitary-testicular axis) following a steroid cycle, enhancing endogenous testosterone
production. Many athletes and bodybuilders use clenbuterol for its benefits — but there are several dangerous unwanted effects
to concentrate to. Many bodybuilders depend on clenbuterol
earlier than an upcoming performance or competition to trim off further fat.
A secondary effect of this drug is that it helps curb your appetite so that you just absorb fewer energy.
Testosterone is usually referred to as the most important hormone for muscle progress,
strength, and athletic performance. D-Bal is
designed to imitate the effects of Dianabol,
some of the well-known anabolic steroids. Joe and Ben Weider repeatedly emphasized the introduction of the
International Olympic Committee (IOC), which dealt with the drug testing,
to the competitors.
Alongside with their intense workouts, many
bodybuilders additionally rely on varied dietary supplements to enhance
their muscle development and performance. One of essentially the most generally
used substances by bodybuilders is testosterone cypionate.
This powerful anabolic steroid is commonly taken in excessive doses to maximize the results on muscle growth.
However, the question arises, how a lot testosterone cypionate do bodybuilders really take?
Let’s dive into the world of bodybuilding and discover
the dosage practices of those devoted athletes. Testosterone is an anabolic steroid that has been shown to extend muscle mass
and strength, in addition to enhance restoration occasions after exercises.
In men, its levels enhance throughout puberty to advertise the event of male sex traits, such as body hair development, a deeper voice, intercourse drive, and elevated height
and muscle mass. Some opposed results of corticosteroids are muscle loss,
fatigue, and water retention (including moon face). We typically see
these unwanted facet effects persist for several weeks or months until
endogenous (natural) testosterone ranges get well. Females usually solely have 5–10% of testosterone
in comparison with males; nevertheless, it remains
an essential hormone for confidence, energy, motivation, and sexual
desire and satisfaction.
It can also contribute to emotions of despair and anxiousness, particularly after stopping use.
In some circumstances, steroid use can trigger episodes of
mania characterized by hyperactivity, racing ideas, and poor judgment.
Women’s golf has gained visibility and respect over
the past two decades. It is essential for readers to grasp that stacks will improve the severity of unwanted side effects.
We typically find Deca Durabolin to be very suppressive of the HPTA, and thus users should administer a PCT following cycle cessation. Moreover, due to a scarcity of androgenicity, Deca Durabolin provides
unique safety to hair follicles on the scalp and
helps to scale back pimples. Furthermore, a lack of aromatization can exacerbate HDL
cholesterol, as estrogen is cardioprotective.
This aids in normalizing hormone ranges for optimal physiological and psychological health, in addition to retaining results from
a cycle. We have found that DHT-related unwanted side effects are largely
decided by genetics. Thus, some people may expertise vital hair loss from a
low dose of Anavar.
Whereas others may expertise no hair loss whereas taking high doses of trenbolone.
They key word there might be “can.” Anabolic steroids what are the side effects of coming off steroids (jointjedraaien.nl) very highly effective, and so they
affect each of us in a special way. One of the largest
pitfalls for both men and women who use anabolic steroids is that they think the results or side
effects will mirror that of their friends. With shorter but more intense workouts and extra time for recuperation, they don’t overtrain, however give
the muscular tissues extra time to rest and develop.
Primobolan is usually stacked with different
compounds for enhanced results, such as trenbolone or halotestin (when cutting).
Regardless Of being an oral steroid, Anavar also does not
pose vital risks to the liver in therapeutic dosages, because the kidneys help to process Anavar,
taking the pressure and workload off. Anavar additionally has gentle unwanted aspect effects; due to this fact, it is uncommon to watch poisonous results in modest dosages.
Transient testosterone suppression is more likely to be reasonable, with levels generally normalizing in a matter of weeks
or months (for most users).
However, Dianabol tablets can have an result on certain hormones in the physique significantly male hormones such as testosterone.
These individuals who have used anabolic steroids understand how much they will increase muscle gain and fat burning.
Also, they may help to make us extra determined, driven, and aggressive in the gym.
Combining a number of steroids, generally recognized
as stacking, can improve muscle growth, strength, and restoration. For example, Testosterone
supplies a stable base, Dianabol boosts speedy gains, and Deca-Durabolin helps joint health.
A well-planned stack maximizes advantages whereas balancing unwanted aspect
effects. Whereas anabolic steroids can help with muscle progress and efficiency, abusing them can lead to severe well being
issues. At All Times observe medical recommendation and keep away from self-medicating to stay safe.
Positive, your muscular tissues might get bigger, but water
retention can leave you wanting bloated or unnatural.
There’s more on this in unwanted aspect effects of anabolic androgenic steroids abuse.
Anadrol (oxymetholone) is probably equal to Dianabol when it comes to muscle mass and weight
gain, in our experience. Nevertheless, Anadrol does have a tendency to trigger
harsher unwanted aspect effects; hence, why it’s ranked number two on this listing.
Bodybuilders in our clinic sometimes gain 25–30 pounds of weight
during their first Dianabol cycle, with roughly two-thirds
of this being lean muscle and the remaining being water retention.
The odds of harm occurring on Superdrol are excessive compared to other anabolic-androgenic steroids (AAS),
as a result of power levels typically growing drastically in a
brief area of time. Thus, bodybuilders must be cautious regarding lifting as heavy as
potential on Superdrol, with a quantity of of our sufferers experiencing ruptured hernias and requiring emergency medical surgery.
Anavar will have a negative impact on ldl cholesterol, inflicting
a gentle to average increase in blood strain. Nevertheless, we find
this adverse impact to be significantly much less troublesome compared to the cardiotoxicity of other
anabolic steroids.
Nevertheless, we nonetheless see AST and ALT liver enzymes rise due to trenbolone passing by way
of the liver upon exit. Trenbolone is not particularly hepatotoxic as a end result of it being an injectable
instead of a C-17 alpha-alkylated steroid. Trenbolone’s
androgenic rating of 500 vs. testosterone’s 100 demonstrates its uncooked energy in this regard.
Testosterone is predominantly administered through intramuscular injection; nevertheless, it’s also available orally (known as testosterone undecanoate).
Dianabol can also be liver poisonous, being a C-17
alpha-alkylated steroid, thus having to cross via the liver in order to turn out to be lively.
We find such fluid causes an enormous and easy look to
a user’s physique, with very full and puffy-looking muscles.
Gynecomastia in men and masculinizing results in ladies could additionally be irreversible.
So while steroids can supply spectacular outcomes, additionally they come with high dangers and potential
legal consequences. They’re recognized for their potent muscle-building effects, but in addition they include a
host of risks and side effects. You’ll have to balance tren with a testosterone dosage otherwise your sex-drive will hit all-time lows
and your manhood will be nothing greater than a soggy noodle.
Insulin can even reduce muscle breakdown additional promoting muscle development.
Fashionable bodybuilders posing on levels get
lots of hate due to their bloated guts, and insulin additionally contributes to
this. Fulmenpharma.com is considered one of the greatest anabolic steroid platform.
If you are working a cycle or considering one, understanding
how long steroids keep in your system isn’t nearly results — it’s about danger administration.
Whether Or Not you’re competing in a examined sport, working in legislation enforcement, the military, or simply navigating
professional drug screening, understanding detection time is non-negotiable.
Anavar (oxandrolone) is a extremely popular anabolic steroid amongst men and women. Despite its excessive market price, it’s usually coveted due to its versatility.
D-Bal from Loopy Bulk is likely considered one of the
most popular and 100 percent authorized alternate options to Dianabol manufactured in an FDA-approved lab.
However, the beneficial amount of dose should be used to prevent unwanted side
effects. Under the pressure from FDA, CIBA banned the manufacturing of Dianabol in the US market in 1983.
After the entire approval of the FDA on methandienone was revoked, the generic production was shut down two years
later. The Anabolic Steroids Control Act of 1990 outlawed the non-medical use of Dianabol in the US market.
But earlier than you get carried away, it’s essential to remember that they’ll even have devastating side effects.
Information exhibits steroid use isn’t only for elite athletes; loads of common gym-goers are getting involved (anabolic steroid use within the UK).
Steroid use in UK bodybuilding steroids vs natural (https://www.kingsburyholisticdentist.co.uk/) is all about gaining muscle, getting stronger, and looking
out higher. Totally Different steroids get picked for specific goals,
but each single one has possible side effects and health risks.
Customers commonly report vital features in muscle mass when using D-bal as a part of their workout routine.
It is usually praised for its capacity to advertise lean muscle growth.
The cause is that many of the “alternative” medicine are both not effective or
have well being dangers of their own.
Oral steroids may also cause testosterone suppression much like injectable steroids, potentially causing hypogonadism in males.
The above dosages are generally taken by intermediate steroid customers.
We see Winstrol generally produce virilization unwanted
facet effects in girls. However, we now have additionally
seen feminine sufferers prevent such physiological changes by utilizing tiny dosages (5 mg/day).
However, if bodybuilders can afford it, undecanoate might produce equal outcomes to injectable esters, being 20–30 lbs in muscle mass.
This is contrary to other oral steroids, which are C-17 alpha-alkylated and have
to be consumed on an empty abdomen for full results.
Human growth hormone (HGH) is also a managed substance in Japan, and it is unlawful to possess, promote, or distribute it with no legitimate prescription. Japanese authorities are known to implement
these laws strictly, with a concentrate on cracking down on the illegal importation and sale of
HGH and different performance-enhancing medicine.
There are few nations Where Can You Buy Steroids – Nhand.Org, anabolic steroids are still legal and out there to be used.
Anabolic steroids usually are not explicitly listed as a controlled substance in the United
Arab Emirates, however they are nonetheless illegal
to own and use with no valid prescription.
Such loopholes had been addressed with a revision to the 1990 Act in 2004 however workarounds nonetheless exist.
Dr. Jack Parker, holding a Ph.D. and driven by a deep passion for health, is a trusted expert in bodily
well being and authorized steroids. He blends thorough research with hands-on experience to help Muzcle readers obtain their fitness objectives safely and effectively.
Exterior of work, Jack loves spending time with his
household and keeping up with the latest well being developments
and research. Russian athletes could be allowed to compete in the Olympic Video Games if they can demonstrate that they are clean.
They would sometimes have to undergo rigorous testing by anti-doping
agencies, which might include blood and urine checks.
These tests would have to present no hint of prohibited substances for the athletes to be cleared to participate.
The nations the place steroids are authorized only with a sound prescription are Australia, Belgium, France, Germany,
Japan, South Africa and Switzerland. The international
locations where this stuff is completely unlawful are Norway and Sweden, which is the smallest of all the lists offered.
Folks who’ve used steroids or are at present using steroids
know that there are literally hundreds of
thousands of the substances all over the market right now.
Another factor that people that are part of the steroid universe is aware of
is that relying on where you might be situated, the legal guidelines for purchasing
and utilizing steroids can vary, similar to the amount of steroids there are on this very world.
However, possession just isn’t punishable, a consequence reserved for
schedule I, II or III substances. Those responsible of
purchasing for or selling anabolic steroids in Canada may be imprisoned for as much as 18 months.
In Russia, steroids are designated as managed substances, which reflects
their potential for abuse and the need for regulation. Whereas private
use is not explicitly illegal, the framework of legality can be observed as akin to walking a tightrope.
Steroid lovers or athletes eager to bolster their physical prowess must tread carefully in this
territory as a end result of the acquisition of those
substances is extremely monitored. It’s pertinent that
any possession is backed by a legitimate prescription handed out by a
licensed medical professional to stay throughout the authorized
confines. From this examine it is concluded that these substances are easily obtainable without management on the Web, with solely a limited number of sites offering oxandrolone, DHEA and androstenedione requesting a prescription.
They subsequently outlined “one unit of anabolic steroids” as a single 10ml vial of injectable anabolic steroids, or 50 tablets of any oral anabolic steroid.
Larger vials of injectables, similar to 30ml vials, have been transformed and
broken down to the only models previously listed. So, a 30ml
vial could be the equivalent of three 10ml vials and subsequently qualify as three units of anabolic steroids.
Proper medical supervision helps in mitigating the adverse effects of steroids.
It’s crucial to comply with prescribed dosages and preserve regular check-ups to forestall problems, corresponding to coronary
heart points or liver harm. This approach prioritizes affected person security while acknowledging the potential advantages of steroids in a controlled medical context.
The market is flooded with counterfeit and low-quality merchandise
that may pose serious health dangers.
If you are trying to enhance sports performance naturally,
consider natural sports dietary supplements.
The use of anabolic androgenic steroids (AAS) for strength training and
muscle constructing is a widespread follow among athletes and young individuals.
Athletes and bodybuilders are utilizing these substances for numerous functions, corresponding to enhancing muscle mass, strengthening their bodies, and enhancing their performances.
They are unlawful to own, use, or provide them, and not utilizing
a valid prescription or authorisation. Due to their classification remaining
purely as a prescription drug, South Australia has essentially the most lenient legal guidelines in relation to steroids.
In South Australia, steroids are categorised in a special manner to
different states in that they are known as ‘prescription drugs’ underneath the
Controlled Substances Act 1984 (SA). Schedule 1 of the Drug Misuse and Trafficking Act 1985
(NSW) outlines the quantity of anabolic and androgenic steroidal brokers which
corresponds to an ascending classification.
However, anabolic steroids are additionally commonly misused by athletes and bodybuilders looking to
gain a bonus over their opponents. They could take high doses of anabolic steroids to increase muscle mass, energy,
and energy, or to cut back recovery time after intense workouts.
Peptide hormones are substances that can enhance the performance of athletes by stimulating the body’s own production of certain substances like development hormone.
Moreover, the standard and reliability of generic variations must be
rigorously thought-about. Excessive doses of oral AAS compounds may cause liver injury.[3] Peliosis hepatis has been increasingly recognised with using AAS.
Bear In Mind that SARMs, MK 677 and Cardarine are
all prohibited in competitive sports.
Conversely, gender nonconforming male students could additionally be extra likely to disclose AAS misuse than gender conforming male peers partly as a outcome of they’re less
inhibited by standard masculinity norms [8]. To date,
little is understood about the affiliation of GNC with AAS misuse during adolescence.
To bridge this hole, we extracted knowledge from Youth Danger Conduct Survey (YRBS) to estimate the direction and energy of association between GNC and AAS misuse among US highschool college students.
The firm additionally has a robust history of customer trust and satisfaction. Not only
is it safer and extra convenient to purchase from manufacturers, nevertheless it also ensures that you simply’re getting the easiest in authorized
steroid supplements. Not Like conventional medicine, controlled-contribution programs
haven’t any limits relating to the length of time a controlled-activity drug can be available
on the market. In reality, all controlled-contribution medicines are thought of medical merchandise by the FDA, which means
they are thought-about the equivalent of pharmaceuticals.
A SARM stack may embody various SARMs, each chosen for its distinct properties in selling muscle growth, fat loss, or endurance.
By rigorously deciding on and mixing these compounds, bodybuilders can tailor their routine to achieve desired outcomes whereas managing potential unwanted effects.
Low testosterone is believed to extend inflammation and scarring as a means to extend the
number of cells current within the cell tradition. In turn, this implies more muscle fibers are
able to reply more favorably to coaching, and this in flip will increase their capability for progress, all pure anabolic steroids.
SARM legal options supply similar outcomes, corresponding to
revealing lean muscle, encouraging muscle progress in particular areas, kickstarting bodybuilding efforts, and hastening recovery times.
For this purpose, many HGH customers may also embrace T3 in the
cycle, as this can be a thyroid hormone.
Many HGH users will expertise pain within the joints, muscles,
and/or nerves. Some will develop carpal tunnel syndrome, the place a nerve that goes into the
hand is compressed because of swelling. This can cause tingling and numbness within the
fingers, pain, and hand weakness.
HGH is a brilliant, supportive, and synergistic hormone
to use with steroids because of the glorious synergy they have and differing mechanisms of motion.
HGH will improve and construct upon the results of steroids, serving to you to get even more out
of a cycle. By taking GHRH in its pharmaceutical kind, you get a more
even and regular launch of HGH.
If a pharmaceutical firm or manufacturer releases a new medicine, it have
to be tested through a process referred to as “phase I” and then proceed further with
phase I testing for efficacy, dbal authorized
steroids. Generally, in the past, notably with different
supplements, I have experienced zits and mood swings, but
there was nothing noticeable with authorized Steroids Bodybuilding Tablets.
There are various varieties of legal steroids, relying in your fitness goals.
You can discover the most effective authorized steroid for numerous functions, similar to bulking
up, cutting, and strength-building. Legal steroids are
created from 100 percent all-natural components, which is why they’re identified to
be protected and cause minimal to no unwanted effects.
As A End Result Of Winstrol doesn’t have an excessively significant
effect on building mass (7), we see it often used in slicing cycles to help retain muscle
whereas getting leaner. Winstrol has diuretic effects too, growing muscle striations and the visibility of veins (vascularity).
The solely draw back to its water-flushing properties is that glycogen levels can lower inside the muscle cells, decreasing fullness.
For finest results, we discover that stacking Anvarol with other
authorized cutting steroids enhances fats burning and muscle definition. Anavarol’s finest stacking
choices, in our expertise, are Clenbutrol, Winsol, and/or Testo-Max.
Trenbolone is a really powerful injectable steroid
that produces large increases in lean muscle.
Due to an absence of aromatization, it does not trigger any noticeable water retention, making overall weight acquire lower than on Dianabol or Anadrol.
Of note, our research used a cross-sectional design,
which can solely present an indication of association, not causality between GNC
and AAS misuse. Moreover, gender expression and AAS misuse can change over
time, the YRBS knowledge can’t enable us to look at the
impact of trajectories on the finish result of interest. Second, AAS misuse was measured with the lifetime use of
steroids with no prescription in our study.
Though AAS misuse is assessed over the lifetime, it may more than likely occur relatively just lately,
because there is evidence that AAS misuse earlier than sixteen years is rare [13, 21].
Furthermore, AAS misuse in our examine is susceptible
to overestimation bias because of attainable ambiguity of
the merchandise. The wording of the merchandise is “steroids” in YRBS, which does not explicitly state AAS [28], even though the item follows
different items of illicit substances immediately
[29].
If you’ve had a mind or head harm, says UTMB’s Dr.
Urban, and develop profound fatigue and cognitive dysfunction, see a physician—and ideally also an endocrinologist.
If you’re apprehensive that you’re poor in progress
hormone—only one in 50,000 people are, according to Danish scientists—talk
to an endocrinologist about an HGH-stimulation take a look at.
What’s extra, it’s unclear whether or not giving growth hormone to someone within a
traditional range is useful over the lengthy term. He didn’t need surgical
procedure, so he turned to medical literature and began reading up on progress
hormone. Costa Rica has fewer drug restrictions,
so a physician started growth hormone pictures by way of the Anti Aging and Wellness Clinic
in San Jose, progressively rising the dose. Progress hormone is well-liked
among athletes as a outcome of “it is widely believed by illicit customers that growth hormone works,” says Harrison Pope, M.D.,
a psychiatrist at Harvard Medical College. Once More, this comes down to
value and the flexibility to source LEGITIMATE or top-quality generic HGH
kits (of which there are very few).
Sadly, there are some dangers concerned together with hormonal imbalance and
cardiovascular issues. Combining steroid intake along with a healthy
diet and coaching with blood check monitoring is also mandatory.
Again, this process is important for muscle progress and stopping muscle loss
during slicing cycles. Finding the safest steroid for you would not essentially imply a efficiency
loss. The authorized steroid alternate options of today are made to imitate the efficiency of steroids without
sacrificing performance. If you’re new to your first cycle of steroids, seeking to achieve lean muscle, or looking for one of the best steroids for novices, there’s a safe, authorized,
and performing different.
Orals, for instance, come with that well-known threat to the
liver, so it’s out of the question to use them longer. Blood stress and ldl cholesterol will increase are a few of
the other important threat components for normal and high-dose
steroid use. Can there be a more apparent sign of feminine steroid use
than the growth of hair on the face and body?
You additionally get a number of injection site choices, which you’ll
choose to rotate to keep away from ache and irritation. Injectable steroids are
positioned in an oil-based resolution, and it’s this oil that makes IV injection out of the question for steroids.
After all, we’re simply utilizing medical provides when administering steroids.
Being acquainted with the mandatory provides and various
terminology regarding utilizing them provides you with the arrogance you
should proceed with injecting.
Some water retention is widespread when utilizing testosterone; nonetheless, this won’t
be as a lot in comparability with different bulking steroids, corresponding to Dianabol or Anadrol.
Therefore, injectable testosterone is a lot more cost-effective for newbies.
Even experienced steroid customers may be cowards when it comes to taking testosterone suspension, so novices are
extraordinarily unlikely to take pleasure in this.
In actuality, they’d most likely by no means take injectables again if this was their first cycle.
Creating a protected and efficient steroid stack includes extra than just selecting the best compounds — it requires consideration to cycle
size, dosage, and on-cycle well being help.
Arnold Schwarzenegger may know just how efficient Dianabol is, as he and different
bodybuilders (believed to be) used Dbol within the ’70s, serving to him to safe 7x
Mr. Olympia titles. Although injectable Dianabol is available, Dianabol primarily is available in tablet kind.
This format is optimal for bodybuilders who don’t wish to mess with needles because of pain or the implications of a misplaced injection. Dianabol isn’t
as androgenic as testosterone; thus, oily pores and skin and acne are much less doubtless,
though possible.
With Out PCT, you’ll endure from low testosterone signs,
which could be life-ruining, to say the least. After you achieve some experience using a selected steroid, you’ll get a good
idea of if you feel the advantages lowering. You’ll then have the ability to plan your cycles more exactly to gain maximum profit from each steroid.
Tons Of of 1000’s of people have already worked out
the very best means to make use of them, so there’s little reason to
attempt to reinvent the wheel. As it is a fast-acting stimulant,
it ought to be consumed in reasonable amounts for its effects to be maximised, most secure oral steroid for bulking.
In cutting cycles, Anavar and winstrol steroids are attributed with noticeable fat loss, improved vascularity, and
a chiseled look, with hardly any water retention. Better confidence, health club performance, and restoration are
often the subject of comments, though results rely upon dosage,
genetics, cycle support, and diet.
Winstrol is just like Anavar in regard to gains, with Winstrol being barely more practical.
Nonetheless, Winstrol’s side effects are much more severe compared, with testosterone getting shut down, liver harm, and blood strain rising to excessive ranges.
If beginners would like further muscle and fats loss gains, they’ll stack Anavar and testosterone collectively.
Nonetheless, the danger of side effects will increase barely in comparison with running testosterone alone.
A testosterone-only cycle is the most well-liked protocol for newbies.
This is as a outcome of beginners need to expertise massive
features in muscle and power but need to stay away from harsh compounds.
Anavar, like Winstrol, is amongst the few oral steroids that may produce
lean muscle features whereas concurrently stripping fats.
This essay presents a basic define to lead the newcomer to the first time use of anabolic steroids,
efficient and secure, bulking and cutting, cycle plan, and post-cycle therapy (PCT).
One of the strongest Legal Oral Steroids steroids for bulking is D-Bal,
the legal different to Dianabol. D-Bal works by growing
protein synthesis in the physique, which is
essential for building muscle mass. It also helps in lowering serotonin ranges within the body, enabling athletes to work out longer
and harder. Additionally, D-Bal boosts testosterone levels,
which is essential for muscle development. These supplements use pure elements to reinforce muscle progress and enhance
energy. Say goodbye to harmful anabolic steroids and discover the
safe and effective method to bulk up with authorized steroids.
Don’t forget to take a look at the earlier than and after steroid cycle results to see the consequences of those cycles on other users.
Nevertheless, before beginning the primary beginner’s steroid cycle, contact our consultants who will allow you to select the right cycle to avoid side effects, and allow
you to obtain the outcomes you’re after. For more information on Superdrol and to discover other top-tier anabolic steroids,
visit our homepage right here.
A Lot of this is as a result of of Cardarine’s capacity to get more blood circulate to your muscle
tissue. Andarine provides an additional
boost to performance and will increase bone mineral
density, so you scale back harm threat. You’ll get a lean, vascular,
and dry physique with correct food regimen and coaching.
This is the ultimate outcome for any chopping cycle, however you
must put within the work. Shutdown is probably going on this cycle, so you’ll want to add a SERM or a testosterone base early on. Quick, important,
and dry positive aspects with RAD-140 and LGD-4033, while your physique hardening and firming are taken care of by Ostarine with its fat-burning properties.
Sustanon 250 is an effective testosterone ester utilized in bulking cycles to add vital
quantities of muscle and strength. Some imagine Sustanon 250 to be the
best type of testosterone because of it containing both short and lengthy esters.
Usually, we see Sutanon 250 produce distinctive ends in the
early and latter stages of a cycle. Dianabol stays one of the best steroids for building muscle
and bulking up. D-Bal is the legal steroid primarily based on perhaps the most popular anabolic steroid of all time, Dianabol.
Whereas there are numerous authorized steroids in the marketplace,
these 7 are the best.
Clenbuterol is not a steroid; nevertheless, it’s usually stacked with slicing
steroids to ignite fats burning. Loopy Bulk’s Clenbutrol replicates the stimulative effects of Clen to spike
a user’s metabolism. Trenbolone can be a strong fat-burning
steroid and is thus generally utilized in chopping cycles too.
In our experience, using Decaduro alone is not going to yield important
muscle gains. Thus, for maximum muscle hypertrophy, stack Decaduro with D-Bal, Anadrole, Trenorol, and/or Testo-Max.
Also, Deca Durabolin is to be injected, which some people are not comfortable with.
When used properly, you probably can expect to see
most of these optimistic effects. But when abused, corticosteroids could cause several harmful health
results, similar to high blood pressure, irregular heartbeat, osteoporosis and cataracts.
Creatine is amongst the most well-known efficiency support options.
It’s a naturally occurring substance present in meals like fish and meat.
Anavar and testosterone undecanoate are the best oral steroids for beginners as a result of their mild nature and few unwanted aspect effects.
Oral steroids may also trigger testosterone suppression much like injectable steroids, probably causing hypogonadism in males.
Mastoral is a prohormone supplement that is designed to help athletes cut back excess
bodyfat while serving to build lean muscle mass. Significant features in lean tissue,
more durable look and can be made so so long as sufficient energy are consumed, a
key element to successful weight-reduction plan. The results of Superdrol can be very helpful to the dieting athlete as a chopping steroid.
D-Bal was formulated by Crazy Bulk to duplicate Dianabol’s constructive effects
but without the opposed effects. This enables bodybuilders to stay healthy while building muscle, as an alternative of destroying their
well being in the brief or long run. Due To This Fact,
if prestigious athletes are joyful to endorse a complement
firm, it’s a sign that they’re reliable.
This is particularly true with firms that point out the word ‘steroids,’ which is
taboo within the health world. Loopy Bulk is by far the biggest legal steroids brand on social media,
with 11.9k followers on Instagram and 4.8k followers on Twitter.
The solely different noteworthy competitor on social media was SDI Labs, with 2,994 Facebook followers, and Flexx Labs, with
1,671 fans. Authorized steroids provide a protected and effective
way to construct muscle quick.
Anabolic steroids are artificial derivatives of testosterone
designed to considerably enhance muscle development, enhance
energy, and speed up restoration. They replicate the pure anabolic
effects of testosterone, resulting in speedy muscle growth and improved physical performance.
There are so many revolutionary manufacturers with bestselling legal steroids out there.
So, on to the cycle… A simple 8-week cycle of Ligandrol at 5mg/day
will have a newbie making some very nice gains (remembering it’s at all times easier to gain in your first cycles).
While we don’t have anywhere close to the data and experience we do with steroid combos,
SARM customers have discovered that combining SARMs with good synergy provides better results.
Nevertheless, it additionally will increase side effects, relying on how potent the
additional compound is. MK-677 could cause
some serious side effects, especially at greater
doses, which is to be anticipated when discussing a compound
that raises progress hormone ranges.
The latter can put athletes in danger who bear common doping checks if they’ve consumed
a complement that unknowingly contained SARMs. This is why solely taking dietary supplements from reputable firms the
place 100% of the components are sure is a must for anyone
exposed to drug testing, as well as if you want to avoid SARMs altogether.
The World Anti-Doping Agency has prohibited all SARMs since
2008. It is listed within the class of banned substances underneath Anabolic Brokers, which is similar class that steroids are listed in. This implies
that SARMs are never permitted, and any drug exams
that come back optimistic for any SARM might be handled based on the rules of your explicit
sport. Since turning into a banned substance, dozens of skilled
athletes have tested constructive for SARMs over time and have been banned or penalized.
Generally, SARMs what are the best steroids to take
(https://www.oaza.pl/articles/is_creatine_bad_for_you_the_dangers_of_creatine_explained.html) included in supplements,
however these must be taken with caution as, as quickly as again, you can not often inform the origin of the SARM in these
instances.
First of all, I was surprised by the immediate enhance in workout performance it gave me.
I’m impressed with TestoPrime and highly advocate it to anybody
who needs to construct muscle and really feel nice.
Not solely might I blast through my exercises, however I was additionally extra productive at work and had the vitality
to play with my son within the evenings without feeling exhausted.
TestoPrime is manufactured by Wolfson Manufacturers and
is a much better alternative to injectable steroids. If
you need to get ripped and construct muscle, TestoPrime is a superb selection.
By the second week, I noticed a real spike in my energy ranges,
with a 10 lbs. By the tip of the first week, I had lost excess fat in my love handles, and my muscle definition had improved.
Due To This Fact, it’s usually stacked with Anadrol, testosterone,
or trenbolone. We discover that endogenous testosterone ranges usually normalize several weeks following cycle cessation. Edema is a common facet impact as a result of testosterone rising aromatization. Throughout this course of, estrogen ranges rise, causing water retention in customers.
This hormonal shift typically decreases muscle definition whereas growing
the chance of bloating and gynecomastia. Thus, controlling estrogen ranges is necessary for sensitive
users to forestall the accumulation of feminine breast tissue.
Some examples of anabolic Christian Bale steroids are
Deca-Durabolin, Winstrol, and Clenbuterol.
Girls are typically smaller than men, so that you shouldn’t match
your male peer’s dosage. Contains a selection of amino acids like arginine,
lysine, and glutamine that might potentially trigger diarrhea or bloating.
Accommodates several amino acids which might cause unwanted effects like
gastrointestinal discomfort, similar to bloating,
diarrhea, or abdomen cramps. Doping with erythropoietin might raise
the risk of significant well being problems.
Authorized steroids are designed to give you the same muscle and
strength-building benefits as actual anabolic steroids
with none of the harmful unwanted aspect effects.
When considering steroids for bodybuilding, you are looking
at several components affecting their value. Brand reputation and efficiency greatly influence pricing;
high quality assurance from worthwhile manufacturers often means larger costs.
You must also pay attention to hidden costs, like medical charges for unwanted effects.
If you’re exploring cost-effective options and knowledgeable
decision-making, there’s more to uncover. As you embark on your journey with
authorized steroids, it’s vital to comply with the beneficial dosage and instructions for optimal
results.
After the primary few days, I started to expertise increased stamina and vitality ranges, despite the precise fact that it
is caffeine-free. The good news is that Testol one hundred forty is a pure, secure,
and legal alternative to Testolone, that means no unfavorable side effects.
Several research have confirmed that zinc supplementation improves physical performance and reduces recovery occasions.
D-Bal is Crazy Bulk’s legal various to Dianabol, an anabolic steroid whose risks far outweigh any benefit when natural options like D-Bal
are available. Crazy Bulk jumped in the authorized steroids ring with Clenbutrol to imitate the consequences
of the banned substance Clenbuterol. Alcohol consumption can improve hepatic pressure during steroid cycles.
Moreover, combining oral anabolic steroids with prescribed hepatotoxic medicines may
cause liver issues. In this case, our patient’s physique temperature increases by approximately 1 diploma.
In conclusion, stacking legal testosterone steroids can enhance the overall effectiveness of your supplementation regime.
Be certain to determine on the proper combination of dietary
supplements to match your health objectives and always seek
the advice of with an expert or a trainer before starting a new complement stack.
D-aspartic acid is an amino acid identified for its
position in testosterone production. This important component triggers the release
of luteinizing hormone (LH), which in flip stimulates the Leydig
cells within the testes to supply more testosterone.
This is especially true for worldwide customers and those living in remote areas.
One essential factor to consider when shopping for authorized steroids is the value and availability of these supplements.
Taking these precautionary measures goes a great distance in guaranteeing that
you simply take pleasure in the advantages of authorized steroids without compromising your safety.
Prime Male can additionally be recognized for its fat-burning capabilities, allowing customers to
realize a lean, toned physique in a shorter timeframe.
Then there’s Panax Ginseng, identified for its capability to sharpen cognitive perform
and reduce fatigue – essential for those grueling exercises.
This is not nearly libido – it is about maintaining
muscle mass, power, energy, and overall vitality.
That Is where Testo Prime is obtainable in, and let me inform
you, it is a powerhouse. The use of anabolic steroids
is very regulated in most international locations, together with the Usa.
These substances are categorised as Schedule III controlled substances under the Anabolic Steroid Control Act, and their
possession or distribution and not using a prescription is unlawful.
By totally reviewing the security profile of each ingredient in the supplements, we
minimized the risk of side effects.
Steroids might give you the pump you have to practice tougher than you in any other case may.
One of the most contentious and frequently mentioned topics in the bodybuilding scene is this one.
Both pure and steroid bodybuilding have lengthy been popular, and each group believes that
their approach to bodybuilding is “correct”. Let’s first look at the variations between the 2 earlier than making a selection as to which is superior.
The use of anabolic steroids is highly regulated in most countries, including the Usa.
Look for visible unwanted side effects corresponding to gynecomastia, site swelling from injections, and hair loss.
Mispronunciation of steroid names also can point out somebody’s information and expertise with steroids.
Natural bodybuilding promotes psychological and bodily power, helps construct a powerful immune system, and may be easily
integrated into any way of life. Gynecomastia, or the enlargement of breast tissue in males, is a standard facet effect of steroid use.
Mental resilience in pure bodybuilding is commonly missed however is equally essential.
It’s about persisting when progress plateaus, pushing through difficult exercises, and staying motivated despite
slow results. It’s not uncommon to see big bodybuilders training with small weights.
They don’t should raise heavy because the medication are doing many of the work.
Even if you’ll find a way to get to his levels of physique
fats as a natural bodybuilder, achieving such insane cuts is
sort of exhausting.
Make sure that you are taking time out every day because
this will enhance how you feel about your
training. It doesn’t instantly alter your gene’s expressions,
in contrast to steroids. Steroids’ direct affect
on gene expression evokes rapid modifications in muscle mass.
These unregulated sources could be dangerous as a end result of the products may be contaminated, mislabeled, or counterfeit.
It is simply really helpful for people with confirmed low testosterone levels and signs
that have an result on their health or quality of life.
Diagnosing low testosterone requires blood checks, typically performed in the morning when testosterone ranges are at their highest.
Medical Doctors additionally contemplate
a person’s medical historical past, symptoms, and way of life components before recommending remedy.
If your harm turns into extreme or lasts for a protracted
period, then you should seek medical recommendation from your PT or doctor.
It doesn’t happen to everyone, but if the lifter
in question doesn’t have these symptoms, it’s another signal he may be natty.
This is amongst the causes being natty can be so rewarding (and sometimes frustrating).
The final sign of consistency, dedication, and self-discipline is chasing that objective daily, figuring out it won’t come fast.
Not to say you cannot develop a powerful pair, because you can, but generally,
if somebody has ridiculous comic e-book character traps,
it’s a telltale sign.
To further harm his probabilities in this 100-day steroids vs natural
competitors, Brandon additionally plays competitive tennis,
which provides a number of hours of cardio on prime of
his exercises. There has never been any formal research on the distinct coaching variations, supplement use, and contest prep of these that are enhanced vs those who are
drug-free. This article was lined in nice detail within the
November issue of MASS, however here is a simplified version. The analysis was from the group of Daniel Hackett’s lab, who does superb research on muscle physiology.
These embrace the advantages they provide, the components and
their dosage, buyer critiques, and the worth and assure provided by the producer.
Always seek the guidance of with a healthcare skilled
before starting any new complement routine, and do not neglect that dietary supplements aren’t an alternative
to a balanced diet and regular train. However if you’re beneath 18, or new to bodybuilding, or pregnant,
then you’re going to wish to avoid using any complement, especially these ones.
While you shouldn’t count on prohormone / steroid like effects with laxogenin, it will still enhance power and recovery.
So while steroids can offer impressive outcomes, in addition they include excessive dangers and potential authorized consequences.
They’re produced from natural components, reducing the danger of unwanted aspect effects.
However, not all-natural steroid options are made equal, and choosing the right one may be a daunting endeavor.
It requires some effort to avoid fraudsters in the marketplace offering harmful and unlawful steroids for vigorous exercise.
It is essential to rigorously consider the benefits, risks, and steering
of a healthcare supplier earlier than making any
decisions. Jeff Nippard first coated the potential of pure
bodybuilding and defined how a lot development you presumably can obtain without leaning into steroids.
Nippard is the former Junior Mr. Canada title holder and in addition held the
Canadian national report for bench press as a
pure powerlifter. He believes that he’s not a fully elite example of a natural bodybuilder.
Nevertheless, Nippard’s growth is an effective benchmark to assume how to make synthetic testosterone (Cody) much progress a person can naturally obtain. To use
authorized steroids the right means, pay consideration to
attainable risks. Authorized steroids, together with wholesome meals and common workouts, can help construct
your physique safely, avoiding the harm from unlawful steroids.
I respect his distinctive insight on a wide range
of matters and I’m grateful to share them.
I additionally respect his want to stay nameless as he
is nonetheless on the front lines treating patients. To discover more of AMD’s work, remember to try The Forgotten Facet of Drugs on Substack.
Not solely does ldl cholesterol come from the food plan, but cholesterol
is synthesized in the body from carbohydrates and proteins in addition to fats.
Therefore, the elimination of cholesterol wealthy
meals from the food plan does not necessarily lower blood
cholesterol levels. Some research have discovered that if certain unsaturated fat and oils are substituted for saturated fats, the blood ldl cholesterol degree decreases.
This popular diet drug poses the risk of unwanted aspect effects,
as with numerous other slimming capsules. The
concern comes in with the reality that clenbuterol is also absorbed by a quantity of tissues and organs in the body.
This can lead to cell demise, when cell dying is experienced within the coronary heart it could lead to heart failure.
The poisonous properties of the drug also play a job in liver failure and different circumstances.
These drugs that embody testosterone and growth hormone, are often used illegally and not utilizing a prescription and are sometimes abused so as
to improve one’s athletic efficiency and look. For example, corticosteroids may help folks with asthma breathe during an attack.
AASs are artificial versions of the primary male hormone
testosterone.
Also, estrogens are formed from testosterone and androstenediol peripherally
in the liver. The steroid hormones are synthesized in the adrenal cortex,
the gonads, and the placenta; are all derived from ldl cholesterol and lots
of are of scientific importance. Steroid hormones are synthesized within the mitochondria and easy endoplasmic reticulum.
Because they’re lipophilic, they can’t be saved in vesicles from which they would diffuse easily and are due to this fact synthesized
when wanted as precursors. Upon stimulation of the parent cell, steroid hormone precursors are
transformed to active hormones and diffuse out of
the father or mother cell by easy diffusion as their intracellular concentration rises.
Call your healthcare supplier promptly for issues that might be more
severe, like modifications in your vision, increased
urination, yellowish skin or whites of the eyes, swelling,
or indicators of infection similar to fever.
Examine along with your doctor about the dose
and how lengthy to make use of proton pump inhibitors.
If you must keep on them for a very lengthy time, your physician could prescribe antibiotics to help forestall pneumonia, since reducing abdomen acid can lead
to bacterial overgrowth. Docs also might advise taking
calcium and vitamin D supplements as a end result of proton pump inhibitors can deplete those.
Corticosteroids interrupt the chemical indicators that set off inflammation and prevent your immune cells from causing damage.
This Is what you should know about how corticosteroids work and what ailments they deal with.
Steroids additionally scale back the activity of the immune system, the physique’s natural
defence in opposition to sickness and an infection. Steroids intently copy the consequences of hormones normally produced by the adrenal glands, that are 2 small glands discovered above
the kidneys. Do not eat liquorice whereas taking prednisolone,
however, as this can improve the quantity of the medication in your
body. Tell your physician if you take some other medicines, together with natural remedies and supplements, earlier than beginning steroid tablets.
Healthcare suppliers use cortisone shots to treat inflammation throughout your body.
In postmenopausal women, the treatment of osteoporosis with anabolic steroids, similar to
nandrolone decanoate, just isn’t advocated given the success
of oestrogen substitute and, extra just lately, with the introduction of
the biphosphonates. The rat levator ani muscle is part of the perineal advanced
of striated muscular tissues that envelope the rectum.
This muscle enhancing steroids – https://www.lagodigarda.com/booking/Pages/medicamento_para_emagrecer_1.html – was
chosen because earlier workers had reported that testosterone
propionate stimulated the expansion of the perineal complex in infantile rats, and, moreover, this complex was easily separated
from other tissues. In distinction, there was a much smaller unparalleled enhance within the weight of the
seminal vesicles.
This is one other of the original steroids from
the ’70s and it retains its reputation at present.
The traditional dose is between 200 and 600mg per week for
up to 12 weeks. It is used by docs occasionally to assist treat
anemia, AIDS and even some cancers. This is among the
original steroids that has been in use for the reason that 1970’s.
If you take it you’ll have to cycle it for between 2 to 6 weeks with a most of 1mg per day.
Animal fat with stearic acid and palmitic acid (common in meat) and the fats with butyric acid
(common in butter) are examples of saturated fat. Mammals retailer fat in specialised cells,
or adipocytes, where fat globules occupy many of the cell’s quantity.
Crops retailer fat or oil in lots of seeds and use them as a
source of energy throughout seedling development. Unsaturated fat or oils are usually of plant origin and contain cis unsaturated fatty acids.
Cis and trans point out the configuration of
the molecule around the double bond. If the
hydrogen atoms are on two completely different planes, it is a trans-fat.
The cis double bond causes a bend or a “kink” that stops the
fatty acids from packing tightly, keeping them liquid at room temperature (Figure 2.three.5).
Nonetheless, they’ll have significant unwanted aspect effects
at high doses or when prescribed long-term. The extra
testosterone will have an effect on every organ and
cell perform inside the body. Corticosteroids or glucocorticoids—commonly known as
steroids—are prescription medicines that scale back irritation in the
body.
It features a mixture of each oral and injectable steroids to give
you maximum ends in minimal time. Tren Hex (Trenbolone Hexahydrobenzylcarbonate) is the large ester form of the anabolic steroid Trenbolone.
It has a protracted half-life of about 14 days and slowly releases Trenbolone
into the physique after injection.
For them, sports pharmacology is not a brand
new notion, but it’s nonetheless unknown and untested.
You will never know, for certain, whether or not doping is a viable various to simply
training alone until you find out about all of the features.
Bodily and psychological stressors are increasing quickly in sports
as athletes compete for recognition and victory, whereas training can sometimes push
human capacities to their limits. The athlete thus begins to ponder how far they can prolong these limits.
If you are in search of on-line steroid outlets for
instance you search Anabolic Steroids for sale and directed to
some on-line steroid retailers you will notice completely different classes.
Every anabolic steroid comes with a brief record of
attainable unwanted facet effects that customers need to concentrate
on. These are most often prevented with safe use or treated within the
recovery period after a cycle. The best-grade Steroids For Sale and
dietary supplements from our high-quality range will help you faucet your actual strength potential, and you’ll obtain your fitness goals at a speed unmatched earlier.
Purchasing anabolic steroids with no prescription is illegal in the USA.
In the USA, anabolic steroids are Schedule III managed substances under the Anabolic Steroid Management Act.
So, like all forms of Trenbolone, Parabolan is considered
a steroid with versatile makes use of and one worth taking a look at, even if gaining big mass isn’t your major objective.
This is a steroid with a quantity of advantages and
a few disadvantages you’d be familiar with. HCG at 2500iu/week for 2-3 weeks (2 shots/wk of 1250iu spread evenly
Mon/Thurs). Regardless Of Tren being a dry compound, the other
two will result in water retention, so contemplate adding
some cardio to your exercises to reduce any spike in blood pressure.
With no two folks being the identical, men will speak about paranoia,
extra aggression, jealousy, anxiousness, and other
emotions that may turn into tougher to regulate as you increase the
dose or cycle size. Injecting it every other day is the usual protocol to take care
of constant peak ranges. You can inject daily when you choose, but there won’t be a noticeable benefit in comparability with each different
day injections.
We source our steroid-related merchandise from respected manufacturers and conduct thorough quality management checks to ensure you receive
only the most effective. Our commitment to high quality
means you should purchase steroids on-line from us and trust that every product you purchase is secure, efficient, and dependable.
You may be given a blue or red steroid remedy
card to carry with you, which warns healthcare professionals
that you are taking and additional on the lookout
for anabolic steroids for sale.
Nevertheless, we only stock supplements that align with the guidelines
in the areas we ship to. Our mission is to provide protected and effective performance-enhancing substances for accountable grownup use.
Bear In Mind, managing side effects is a proactive process that requires responsible
use, open communication with healthcare professionals, and self-awareness.
By prioritizing your well being, monitoring your body’s response, and
looking for steering when needed, you possibly can reduce
risks and optimize the benefits of Anavar utilization. By following the following
pointers, you possibly can enhance your probabilities of buying Anavar safely and obtaining a genuine, high-quality
product. Responsible purchasing practices and thorough
research are key to safeguarding your health and maximizing the advantages of Anavar utilization. During these
cycles, people should continue to prioritize proper diet, intense coaching, and adequate rest for optimum results.
We must have a glance at both the great and the bad to get a whole thought of what Trenbolone is doing for folks and whether you should buy
Trenbolone or not. With your large enhance in strength comes supercharged pumps,
and you’ll really feel it continually throughout
workouts. Even when you’re not on the health club, you’ll enjoy the extra fullness and
hardness that Tren delivers, even should you must go a couple of days with out figuring
out. We can see how a lot the professionals of Tren-Max outweigh the small
number of minor disadvantages when evaluating it to Trenbolone.
On the downside, comparable unwanted effects to different
steroids are nonetheless potential as a outcome of Tren is a progestin, which, sorry to say, can even make you more vulnerable to gyno.
Our stock includes every thing from powerful injectables to
cutting-edge SARMS, HGH, and peptides. Whether you are a seasoned bodybuilder or a health
enthusiast, you’ll find precisely what can steroids do to you you should attain your targets.
Plus, our aggressive costs, coupled with regular reductions and promotions,
make it simple to get one of the best value for your money.
It is price noting that right now, buying high-quality steroids in Ireland and the United Kingdom is
as tough as ever due to the growing number of fake merchandise on the market.
We strongly recommend checking local legal guidelines earlier than placing an order.
Stacking also can help individuals tailor their cycles to their
specific goals, whether it’s gaining muscle mass, chopping fat, or bettering athletic efficiency.
Moreover, by strategically combining compounds, users may have
the ability to obtain their desired outcomes extra effectively and effectively, making the most
out of their Anavar cycle. Anavar, also called Oxandrolone, exerts its results within the body by way of several
mechanisms.
Franco Columbo’s bodybuilding regime remains a
benchmark for these seeking to realize peak bodily situation. However, if he felt a specific muscle group needed extra
relaxation or a different focus, he would modify his routine
accordingly. On the fourth day, Franco Columbo engaged in an active relaxation day.
Franco would start his workout with squats, known as the ‘king of all exercises’,
focusing on the whole decrease body, together with quadriceps, hamstrings,
and glutes.
Don’t permit anything stop you should you aspire to be as giant and strong as Franco or if you need to obtain greatness.
Franco Columbu has a close bond with Arnold Schwarzenegger, a legendary bodybuilder.
For 5 and a half decades, the 2 had been close associates and
training companions. Even earlier than he declared his candidacy for governor of California, Arnold
referred to him as the “Sancho Panza” to his “Don Quixote.”
Boyer Coe publicly stated at a seminar after the contest that the winner of the
Mr. Olympia “had legs that appeared like they belonged in a hen nest”.
Roger Walker felt that Arnold acted like “an asshole” onstage.
He by no means competed once more in another bodybuilding contest, feeling like he gave this
contest his all however was the victim of politics and conspiracy.
After the prejudging was over, Arnold sought recommendation from his
closest pals. He knew the contest was close and he felt a little out of place onstage after
a 5 year absence.
Ahola points out with a wry smile thatone of Samuelsson’s endorsements is
with Valtra, a truckingcompany. “That is motivation,” says Ahola, “as a result of it’s aFinnish company, they usually did not ask me.” Wilhelmsays the test of final energy must be elemental andsimple.
“Choose up a barbell, two palms, and clear it to thechest,”
he says. Reeves, now an IFSA official, and Hoeberl discuss institutingsteroid tests within the next couple of
years, however nobody isconvinced that will happen. There remains
to be a feeling thatseemingly superhuman feats corresponding to pulling 22 tons of truck can’tbe performed without chemical help.
Like Schwarzenegger and Ferrigno, Columbu is commonly credited as
being one of many males answerable for serving to to deliver the sport of bodybuilding into the mainstream.
His presence on and off the stage was plain, and those close to him keep
in mind him as a kind soul and an inspiration. “Boxing’s too rough in your face and head,” Columbu
stated of his departure. Instead, he began focusing his efforts on weight lifting and bodybuilding — and in 1965, met
one other well-known bodybuilder, Arnold Schwarzenegger, with whom he would establish a lifelong
friendship. His philosophy of incorporating food plan, train, rest, and
mental well-being right into a complete way of
life continues to encourage and information modern health fanatics.
Recognized for his aesthetics and conditioning, Frank Hillebrand died of
a heart attack at the age of 45 in 2007. His finest placing at a pro
present was a seventh-place end at 1990 Mr. Olympia.
The cause was reportedly a coronary heart assault, and despite CPR being attempted, he was pronounced dead in the fitness center.
Two residents who have been on the pool noticed him fall in and immediately pulled him out.
Although they were able to revive him and call paramedics,
Atwood passed away at a nearby hospital on the age of 37.
The coroner’s report showed that Atwood died of a
massive heart attack.
He was another undisputed legend who earned himself a place not lonely on the health stage but also within the movie
business. Ed Corney appeared within the movie, Pumping
Iron, the identical one which was acted by Arnold Schwarzenegger and Franco Columbu.
The incontrovertible reality that Corney dined with kings makes him a king as nicely.
He acquired a reported $1 million in compensation (equivalent to $4.5 million in 2021)
for the accidents that stored him out of the sport for a number of
years. Columbu competed again in 1981, successful Mr.
Olympia, after which he stopped. He additionally had a love relationship
with one other chiropractor, Anita Sanangelo. Later, in 1965, he took a trip to Germany for
a bodybuilding competition the place he finally met Arnold
Schwarzenegger. Frank Columbu was a contented husband who cherished his
time together with his beautiful wife, Deborah Columbu.
References:
Steriod Side Effects
You can by no means have this guarantee with underground
lab-sourced Testosterone Cypionate. Any regulators or authorities does not approve these labs, so there is
no oversight on the quality of the facilities the place the steroids are being manufactured (or their
ingredients). Some men (we might name them the fortunate ones) are genetically programmed to
withstand a better DHT level, whereas others are very sensitive to DHT, and solely a small rise results in hair loss.
And Testosterone Cypionate won’t shock you with surprising unwanted effects.
As an unaltered testosterone hormone, we all know precisely what it does – unlike lots of the
funky unwanted effects that usually include modified AAS like Trenbolone.
Even although Testosterone Cypionate is no doubt the most secure
steroid that males can ever use, it’s still possible for opposed unwanted effects to rear their heads.
Avoiding regular alcohol consumption is very suggested as alcohol consumption of this nature is
more toxic to the liver than any Anabolic steroid.
Additional, avoiding as many over-the-counter medicines as potential is really helpful as many over the counter drugs are much more
poisonous to the liver than many anabolics. A typical bulking cycle lasts between 8 to 12 weeks, depending on the steroids used and
the user’s experience level. Extended use can increase the risk
of unwanted effects, so it’s crucial to plan cycles carefully and permit adequate time for restoration. The
primary cause individuals take anabolic steroids is to construct muscle
size and strength. In this article, we reveal the best steroids
for mass and the dosages utilized by bodybuilders
today.
Nonetheless, our patients have administered SERMs with such stacks, together with Nolvadex, enabling us to regulate and avoid breast tissue formation. We also recommend preserving cycles comparatively brief to reduce hurt to this
organ. A individual can usually reverse liver damage
and inflammation from this stack if they stop drinking alcohol, refrain from taking different hepatotoxic medicine, and complement with milk thistle and
TUDCA. Dianabol also increases estrogen levels by means of aromatase, whereas Anadrol
doesn’t aromatize however directly stimulates estrogen at a receptor level.
Something from TRT dosing or aiming to dose just above your natural testosterone ranges right up to blasting doses
on the highest level. Extra than another anabolic steroid, we can safely use Testosterone
Cypionate at relatively excessive doses with minimal threat or extreme unwanted aspect
effects. Medically, anabolic steroids can treat hormonal
problems, sure cancers, osteoporosis, and other uncommon conditions.
Outside of medicine, both ladies and men use steroids to improve athletic performance and alter bodily look by growing muscle mass and lowering physique fat.
Beneath are some of the most popular anabolic steroids used in bulking cycles.
For slicing, a common Testo Max dosage ranges from 300 to 500 mg per week.
The fact is that such a mixture can be onerous to run because of hormonal imbalances which may happen.
This is the primary query new customers will usually ask as
a outcome of in search of out the very best quality and purest type of Dbol for best results and security causes is sensible.
When it involves pharma-grade Dianabol, it is a very rare product
certainly. If we could gather all the positive critiques
of Dianabol, it might fill a hundred cellphone books.
This isn’t shocking when you realize that Dianabol has been used for decades by a
few of the world’s greatest bodybuilders – optimistic outcomes are expected.
The right stack decisions can amplify outcomes greatly and
result in a more defined and toned physique. Dianabol was initially designed to boost
the efficiency of American athletes and was broadly used within the Sixties and Seventies.
Anvarol is one of the best promoting legally obtainable chopping
steroid within the Usa. You can even get any skilled help to carry out the Tren cycle based on your
objective. Trenbolone steroid is a potent drug,
however if you eat it correctly, you can mitigate all the above possible unwanted facet effects.
The typical dosing technique for any SERM utilized
in PCT is to start at a better dose (40mg of Nolvadex, for example) and scale back the dosage
by half for the final week solely. Tren is a really
suppressive compound, and you’ll want to run an HCG and Nolvadex to stop crashing your testosterone levels and preserve your gains.
A stack just for superior customers as a outcome of Trenbolone
is the most difficult AAS, so you’ll want to organize for
the unwanted side effects.
Anavar is a C17-alpha-alkylated oral steroid, which means the compound might be fully energetic after bypassing the liver.
Nevertheless, not like other oral steroids, Anavar is not
considerably hepatotoxic. This is as a result of the kidneys, and never the liver,
are primarily responsible for metabolizing Anavar. However,
we find this to be a smaller proportion compared
to other C17-aa steroids. Deca Durabolin is typically taken by girls when attempting to bulk up and achieve lean muscle tissue.
We find that this before-and-after transformation is typical
of someone stacking Deca Durabolin with another bulking beginner steroid
cycle, https://world-clinic.com/wp-content/Pgs/?testosterona_comprar.html,
. Stretch marks may be seen on his right deltoid within the
after photograph, indicating the speedy anabolic results of Anadrol and Deca.
All attainable measures have been taken to make sure accuracy, reliability, timeliness and authenticity of the
data; nonetheless Onlymyhealth.com doesn’t take any legal responsibility for the same.
Using any info supplied by the net site is solely on the viewers’ discretion.
Deca-Durabolin adds to this stack by growing endurance and recovery.
It additionally supports joint well being which is crucial during intense bulking phases where heavy lifting is involved.
Trenbolone will trigger considerably extra cardiac
hypertrophy (enlargement of the heart) and enhance the chance of atherosclerotic
plaque in our experience (11). Trenbolone and Deca Durabolin are both injectable bulking steroids, yet they are fully distinctive in their pharmacology and effects.
Studies indicate that Deca Durabolin is generally well-tolerated
by women when taken in dosages of a hundred mg (6), administered each other week for 12 weeks (thus
translating as 50 mg/week).
You can construct considerably extra muscle than your natural testosterone levels with more circulating testosterone.
Even a relatively low dose will promote increased muscle gains,
with blast doses that may have your T ranges at 4 times their
typical, allowing exceptional positive aspects. New Testosterone Cypionate users shall be very aware of even reasonable
doses and will find the muscle features come on huge and fast in the first cycle or two.
Many bodybuilders and athletes stack steroids in cycles, which can final anywhere from 4 to 16
weeks, depending on their objectives, experience, and
the compounds used. It’s important to note that stacking
steroids additionally increases the danger
of side effects, so cautious planning is important.
They provide the benefit of quick access from the comfort of one’s house, eliminating the necessity
to visit bodily stores. Online suppliers usually present a broad range of
products, including different brands and formulations of Anavar.
Beyond the standard issues, engaging in unlawful transactions to procure Anavar can have
severe legal consequences. The allure of buying Anavar via
unofficial and unregulated channels usually stems from the need for price financial savings and comfort.
Nevertheless, navigating the uncharted waters of
the black market entails a myriad of risks and risks
that warrant careful consideration.
Some bodybuilders opt for legal Anavar alternate options, such as Anvarol,
which mimics Anavar’s fat-burning and anabolic results.
We have not noticed Anvarol inflicting any unwanted effects, although it is possible for individuals to expertise minor reactions.
A liver assist supplement is essential when stacking Anavar
with different hepatotoxic orals, similar to Winstrol,
Anadrol, or Dianabol. Nonetheless, such steroid combinations aren’t
advised, as the potential of hepatic damage or different antagonistic results remains.
Clenbuterol has also been shown to exhibit anabolic effects
in animals. Nonetheless, anecdotally, we don’t see the identical muscle-building properties in humans.
Thus, an Anavar and clenbuterol cycle may enhance fat loss whereas reasonably
growing muscle hypertrophy and strength.
If you’re taking these drugs collectively, your physician might monitor your therapy with warfarin carefully.
One of the simplest methods of taking var is as a
kickstart to an extended cycle. In the primary few weeks of a cycle, individuals are
wanting to see and really feel gains. Utilizing Anavar for the primary 4-6 weeks
permits for greater positive aspects from day one and most synergistic effect.
Anavar pills are out there in numerous dimensions and shapes,
depending on the dosage and manufacturer.
However, a common attribute of Anavar tablets is that they
are often small and round in form, making them simple to swallow.
These pills usually vary in dimension from 2.5mg to 10mg, with larger
doses requiring multiple drugs to achieve the desired dosage.
An essential aspect of the method entails self-reflection and monitoring progress, as
seen by way of the logs of first-time customers. By
maintaining a personal record and interesting with
like-minded individuals in online health communities, one can better understand the impacts of Oxandrolone
and make adjustments as needed. Furthermore, it’s essential to embrace the trial-and-error nature
of this journey, pivoting when necessary and adapting to completely different
conditions. Keep In Mind that stack planning isn’t a
one-size-fits-all process and must be rigorously tailor-made to fit
particular person goals and tolerance ranges. It’s also important to watch your body’s response incessantly throughout a cycle,
adjusting dosages as essential to optimize outcomes and minimize undesired undesirable outcomes.
At All Times method steroid stacking with caution, ideally under the steerage of an skilled.
Therefore, it is strongly recommended to get rid of expired Anavar safely and
not to use it previous its expiration date. Like another medication or complement, you will want to
think about the shelf lifetime of Anavar to keep up its
efficiency and security. Most research on steroid interactions and contraceptives give consideration to more potent androgens or anti-epileptic medicine, leaving a spot in Anavar-specific analysis.
If Anavar induces or inhibits these enzymes, it may
alter hormone ranges, potentially lowering birth control effectiveness.
Oral steroids like Anavar are metabolized by the liver’s cytochrome P450 enzymes, the identical system responsible for metabolizing contraceptive hormones (e.g., ethinyl estradiol).
By following these verification processes and in search of authenticity certificates, you’ll find a way to have the confidence that
the Anavar you may be purchasing is genuine and secure to make use of.
A mild steroid such as Oxandrolone usually requires a
less intensive PCT in comparison with more potent options. A typical Oxandrolone
PCT would incorporate selective estrogen receptor modulators (SERMs) like Clomid or Nolvadex that aim to restore testosterone manufacturing and retain muscle
features. It’s important to begin PCT shortly after the completion of the Oxandrolone cycle – sometimes inside a day or two.
Once an oxandrolone before And after cycle has concluded, it’s important to focus on post-cycle therapy (PCT) to advertise
a easy return to natural hormone ranges and reduce any lingering undesirable outcomes.
By initiating a carefully deliberate PCT, users can guarantee their bodies adequately get well and
keep the gains achieved during the cycle.
However, remember that this timeframe can differ relying on particular person elements and the sensitivity of the testing procedure.
It can lower good ldl cholesterol (HDL) and elevate unhealthy ldl cholesterol (LDL), thus increasing
the risk of cardiovascular disease. Anavar must be used with caution by people
who already have cardiac issues.
In abstract, while Anavar is normally a comparatively protected steroid, it’s nonetheless necessary to pay attention to the potential
unwanted effects. By monitoring your well being and dealing along with your physician, you can decrease the risks and revel in the advantages of Anavar safely.
The nature of such performance-enhancing medication is usually administered within the period of slicing for the preservation of lean body mass by reducing physique fats.
It falls within the category of one of many medication that may make the person look agency with
a good definition with out water retention and bloating.
The finest time to take Anavar is dependent upon your objectives and how your physique reacts to the steroid.
Many people take Anavar within the morning with food to
assist cut back stomach upset. If you’re taking it
greater than once a day, it’s often spaced out evenly throughout the
day.
Anavar can be safe when used under a doctor’s supervision for medical
purposes. Any misuse can result in critical unwanted side effects,
though, so comply with the prescribed dosage rigorously.
Gynecomastia, or the event of breast tissue in males, is one other possible
aspect impact. Though Anavar isn’t as prone to trigger this as another
steroids, it can nonetheless occur, especially if the drug is used in high doses or for extended intervals.
This situation could be embarrassing and should require surgical procedure to right in extreme instances.
Another facet effect males could expertise is testicular atrophy, which is the shrinking of the testicles.
Males produce testosterone in their testes, whereas women produce testosterone of their ovaries.
Right Now, Anavar is towards the law for leisure use in almost each nation in the world, except Mexico, the place it can be bought at an area pharmacy.
DHT (dihydrotestosterone) is a strong androgen that binds to hair
follicles on the scalp, resulting in miniaturization and inhibited progress.
Despite this, Winstrol Depot has a higher degree of hepatotoxic threat than most other injectable AAS, so that
you can’t inject Winstrol without having the identical liver issues as orals.
There isn’t any difference between the strengths of oral and injectable Winstrol.
5mg of both kind is the same amount – what does
differ is how quickly they’re absorbed and used up by the body,
which is reflected of their half-lives listed above. These potent, reliable
supplements are quickly changing the panorama of sports activities diet and are perfect for those seeking a more healthy approach to bodybuilding and weight lifting.
We assessed the value of every legal steroid to ensure it provides
worth for cash. We seemed for dietary supplements
that are competitively priced with out compromising on high quality.
The complement must be used consistently for eight weeks to achieve the best non steroid supplement for muscle growth results, and combined with a balanced food
regimen and regular train routine.
Females will see incredible strength gains with Winny, and lean muscle
gains can break through 10 lbs with the correct food regimen and coaching.
As Soon As the upper dose of these more extreme bodybuilders
is stopped, virilization should subside – however,
this isn’t assured, particularly with extended
and repeated use. This is why such customers will aim to
use high doses right before a competition, to realize maximum muscle definition and dryness
after which ideally allow the body to recuperate without steroids afterward.
Because Winstrol isn’t a bulking or weight acquire hormone, it’s especially suited to these desirous to retain as
lean physique as possible. Winstrol just isn’t a compound you will
use for bulking up, neither is it one that advantages
as a standalone steroid as a outcome of truth it’s not a strong muscle gainer like so
many other anabolic steroids out there. Authorized steroid options usually contain pure
elements that assist to stimulate muscle development, enhance power levels,
and help in muscle restoration. These supplements could be a protected and
efficient approach to obtain significant muscle gains with out using conventional steroids.
This is the optimal protocol somewhat than taking drugs such as diazepam, as they
put additional pressure on the liver (28). Even natural sedative dietary supplements, corresponding
to valerian root, are capable of having an adverse effect on liver values.
Nevertheless, Anadrol must be divided into multiple
doses all through the day to maintain most concentrations of the compound
in your bloodstream.
In truth, the only unwanted effects reported have been a lack of sexual
desire and increased fatigue. The ladies also didn’t expertise any hypertension or androgenic unwanted aspect effects
both (which is opposite to its effects in men). Anywhere from the primary few days as a lot as a couple of weeks is
the time frame that most customers will begin noticing the results of Winstrol.
Your energy might be both maintained and enhanced even on a strict diet.
Winny will add that nice granular look that you just miss out on when utilizing Anavar alone.
Winstrol is well-known for its performance-enhancement benefits, which is why it’s been utilized
by a number of the finest athletes on the planet up to now.
In these cases, athletes aren’t taking Winstrol to enhance their bodily appearance – it is purely about
getting essentially the most energy and velocity. For this reason, Winstrol will
typically be used alone, and the cycle might be more average than those aimed toward physique enhancement.
If you’re severe about bodybuilding and wish to get probably the most out of
your workouts, DBulk is price attempting.
DBulk is one other Dianabol alternative to think about if you want to construct severe
muscle without the everyday unwanted aspect effects. I’m impressed with TestoPrime and extremely recommend it to anybody who wants to build muscle and really feel
nice. TestoPrime is manufactured by Wolfson Brands and is
a much better different to injectable steroids. If you want to get ripped and construct muscle,
TestoPrime is an excellent alternative. I was in a position to lift heavier weights
and push via extra reps with less fatigue, and my post-workout restoration was faster.
After utilizing Testo-Max for one month, I believe
it is a wonderful supplement for anyone trying to construct muscle.
Users simply incorporate Testo-Max into their routine,
with a simple dosage of four capsules a day, taken 20 minutes before breakfast.
Aside from rising testosterone levels, Testo-Max additionally helps in enhancing
power and stamina, which allows weightlifters to train harder and achieve better outcomes.
Trenbolone, also recognized merely as ‘Tren,’ is likely one
of the hottest steroids for rapid muscle features. SARMs (Selective Androgen Receptor Modulators) are
compounds with an analogous structure and performance to anabolic steroids but with fewer and milder unwanted effects.
I’ve heard of guys utilizing it for ten weeks or longer,
however this is discouraged, and extra so, there aren’t any important
benefits to utilizing Winny for so lengthy. 50mg is a regular Winstrol dose
that many males won’t see the necessity ever to exceed.
At this degree, Winstrol’s main effects of dryness, muscle hardness, and vascularity
will become prominent, but unwanted aspect effects ought to remain manageable for most
customers.
The performance-enhancing results of exogenous AAS
in women have been demonstrated based mostly on historical proof from state-sponsored doping programs, from anectodal
reviews and from small dose-response scientific trials of
testosterone administration in non-athlete women. Even although these medication have been banned from sporting competitions,
doping with AAS by feminine athletes continues despite the potential of serious
antagonistic results. These points underscore the necessity for elevated surveillance;
and training and consciousness among the medical community, sports activities community and
lay public. Upon commencing anabolic androgenic steroid use,
it’s attainable that dependency turns into a motivator for continued use.
Round one quarter (Ip et al., 2012) to 1 third (Hildebrandt,
Langenbucher, Lai, Loeb, & Hollander, 2011) of anabolic androgenic steroid users claim to be dependent.
A earlier meta-analysis, including eleven research and fewer than 100 abusers,
has documented that the use of AAS resulted in a fast discount in gonadotropins
and T ranges, which progressively return to the baseline within 13–24 weeks [8].
No information on comparisons between AAS-abusers and non-abuser athletes have been reported.
In addition to the direct actions of anabolic androgenic steroid substances, their use in the type of injectables carries additional potential for harm.
Injected intramuscularly, quite than intravenously, customers usually
don’t perceive themselves to be at excessive threat of contracting blood‐borne viruses (Van Beek & Chronister, 2015).
This might explain the much lower levels of hepatitis B vaccinations or hepatitis C testing seen in anabolic androgenic steroid
customers compared to different injecting drug customers (Anon, 2015).
Creatinine is, for the most part, a product of the spontaneous
nonenzymatic degradation of creatine (Cr) and creatine phosphate (PCr) (159).
The general conversion price for the entire Cr
pool (Cr + PCr) is (almost) constant and roughly 1.7% every day.
Given that almost the entire body’s creatine
is saved in skeletal muscle, an increase in muscle
mass increases the day by day manufacturing of creatinine and might subsequently elevate serum
creatinine ranges with out impacting GFR. The eGFR based mostly on serum creatinine levels is therefore an underestimate
in muscular populations. The major purpose folks misuse anabolic steroids
is to extend lean muscle mass when utilizing them at the
facet of weight training. The technical term for these compounds is “anabolic-androgenic steroids” (AAS).
Typically, all steroids show both androgenic and anabolic
effects of the identical compound. The androgenic
to anabolic ratio is necessary in determining the clinical functions
of the substances that exert an anabolic effect.
The compounds that are utilized in scientific purposes should be diminished with the androgenic impact when offering anabolic remedy.
Behavioral well being professionals ought to become
concerned when psychological unwanted effects are noticed.
Amongst AAS customers there is the assumption that AAS might cause gynecomastia via various pathways, such as elevated progestin motion at the
mammary glands or increased prolactin levels.
Fluoxymesterone is a potent androgen that is produced under the brand name Halotestin. It is a superb substrate
for 5AR and conversion to dihydrotestosterone (DHT) metabolites.
With the addition of a 9-fluoro group, it’s a very potent androgen that has little anabolic activity.
Again, the C-17 methyl group makes oral administration possible, but with hepatic considerations.
Clinical interest within the useful results of those medicine has increased, and ongoing research will continue to uncover novel
makes use of for these brokers and will additional outline their
mechanisms of motion.
In the Uk, anabolic androgenic steroid users
show decrease ranges of schooling in comparison with non‐users (Kanayama, Kean, Hudson,
& Pope, 2013). A cautious historical past must be taken addressing prior use of
AAS, including variety of cycles, cycle length and weekly AAS dose.
We also advise to routinely verify for clinical
indicators that will point out pre-AAS gonadal (dys)function, corresponding to cryptorchidism,
gynaecomastia and infertility. We additionally verify for current use of leisure
medicine, smoking and alcohol intake.
Oxymetholone (Anadrol) is an example of a steroid with each
medicinal and performance makes use of. steroids user
– infront.com, act on the limbic system and
will trigger irritability and gentle despair. Eventually,
steroids may cause mania, delusions, and violent
aggression, or “roid rage.” Gynecomastia is the benign enlargement
of the glandular tissue of the breast (197).
The condition is not to be confused with pseudogynecomastia,
also known as lipomastia or adipomastia, by which
excessive adipose tissue gives the appearance of gynecomastia.
Gynecomastia typically develops throughout puberty, with a reported peak incidence of 65% in 14-year-old boys (198).
The situation stays prevalent all through maturity, with one examine reporting gynecomastia in 40.5% of healthy young men aged 18–26 years (199)
and another reporting detectable palpable breast tissue in 36% of
wholesome grownup men aged 16–58 years (200).
While palpable, in the nice majority of cases the gynecomastia was small in measurement.
AAS are predominantly bioinactivated in the liver, but additionally
within the kidneys and varied different androgen-sensitive tissues (25).
Any support providers or information designed to help people who use AAS
have been thought of. Michele LaBotz, M.D., is a sports drugs
physician who has been caring for athletes at all ranges of participation since 1997.
She is presently in personal practice at InterMed’s sports drugs
clinic in Maine.
In the restoration section, there may be a variable period of low plasma androgen levels.
This may result in scientific signs of hypogonadism similar to fatigue,
lack of libido, erectile dysfunction and depressed mood.
This period is especially feared because it could result in loss of energy
and muscle mass as a outcome of a lower anabolic state and less frequent and intense coaching.
Two research were recognized in this review the place people who discontinued AAS use needed treatment for subsequent psychiatric signs including despair and suicidal ideation [87, 89].
A further eleven research reported therapies for neuroendocrine
issues, primarily with males who had discontinued
their AAS use previous to the onset of signs.
Administering AAS suppresses the hypothalamic–pituitary testicular axis, notably
when used in giant quantities and for long intervals, and inhibits production of testosterone [195].
While your scale weight would possibly decrease, your
power levels might keep secure and even improve, thanks to improved
muscle efficiency and purple blood cell production. Some individuals see great outcomes with simply 30
mg per day, whereas others find 60 mg or more to be effective.Ladies ought
to take significantly lower doses, with 20 mg per day being the maximum.
Larger doses improve the danger of virilization and different unwanted effects.
The proteins and amino acids are included to gas upkeep, muscle progress, and
fat loss. Nonetheless, people with soy or gluten allergic reactions ought to
keep away from this product because of the proteins in its formula.
It won’t cause fast outcomes because it has long esters and thus takes several weeks to peak in the blood.
Nonetheless, with an prolonged cycle and a average dose, Deca is effective
at including average quantities of muscle.
Furthermore, authorized steroid alternate options aren’t prohibited and thus
could be purchased on-line without any legal constraints.
HGH is infamous for causing this appearance due to
its worsening of insulin sensitivity when used long-term (4).
In our experience, there may be little you can do to reduce
visceral fat once it has accrued to this degree. This effect
is brought on by Deca Durabolin’s capacity
to increase intracellular fluid on-cycle in addition to promote overall anabolism.
In this article, we’ll detail one of the best steroids in phrases of outcomes when bulking
and cutting. Anabolic steroid use has become increasingly widespread just lately, with bodybuilding becoming more mainstream.
My aim is to gain as a lot muscle as potential whereas
recouping staying in that bodyfat space or even leaner.
For four weeks, to see where and how is my physique reacting to that molecule, if
every thing is on point. If so I will increase up to 350 mg after blood work
if every thing is in examine I push it at 400 mg then introduce some boldenone at 250 mg.
Beginners ought to analysis extensively, consulting with healthcare professionals and seasoned bodybuilders
to make sure they’re making the best selections for their individual needs
and targets. With security as a paramount concern, the
correct use of anabolic steroids can pave the way for spectacular positive aspects and a rewarding bodybuilding journey.
For example, Dianabol is a fast-acting oral steroid that promotes rapid muscle growth, whereas Trenbolone and Testosterone present long-lasting, dense muscle gains.
Deca-Durabolin not solely helps muscle development but
additionally improves joint well being, making it perfect for heavy lifting cycles.
Together, these steroids ship powerful outcomes for anyone looking to pack on severe
dimension. The decision to make use of steroids marks a big step in any bodybuilder’s journey
in the path of achieving their physique goals.
So PCT served two functions, one to help prevent the side-effects from steroids and one other that will
assist you preserve the gains you’ve made through the cycle.
Steroid cycles usually comply with a 4-8 week periods, which can be resumed as soon as you’ve normalized from the
effects of the steroids. This trio of steroids can produce deleterious side effects, even for experienced bodybuilders, and must be used sparingly, if at all.
The addition of Anadrol will shut down testosterone levels additional, so
customers can proceed operating Nolvadex post-cycle, combined with Clomid and hCG, for a sooner restoration. The greatest concern we’ve with the addition of trenbolone is will increase in blood stress.
Steroid regimes are utilized by bodybuilders who aim to realize
a competitive advantage. Some steroid cycles are solely used to
extend efficiency and physical attractiveness, whereas others are only used for aesthetic reasons.
Trenbolone is extremely well known for creating incredible muscle positive aspects but
also for creating extreme unwanted effects like
insomnia, evening sweats, aggression, and testosterone suppression. Its power makes it one
of the most dangerous steroids for a newbie. Dianabol,
Trenbolone, Testosterone, and Deca-Durabolin are generally used steroids for bulking as a end result of their capability to
increase muscle mass, power, and recovery. Many sports ban injectable and oral
steroid use, and getting caught can mean fines,
suspensions, or even a ruined career.
Users will want to wait slightly longer for them to kick in; nonetheless,
this type of testosterone is usually comfortable and enjoyable for beginners to take.
Furthermore, we discover propionate injections have a tendency to hurt, to the extent of us seeing people limp afterward.
Testosterone produces distinctive features without excessively harsh side effects.
If you’re serious about doing it proper, defend your physique, run your labs,
and let outcomes and restoration drive your decision-making — not ego.
Many users select to run one or both SERMs
depending on their cycle size and compound depth.
This is why athletes and bodybuilders use steroids in cycles, to wean off the consequences of the steroids and to fully flush out the steroids from
their system. It’s additionally better to go into Post-Cycle remedy to overcome the effects of any temper changes
that come as a side-effect of many anabolic steroids.
There are loads of newbie steroid cycles on the market, however you
should understand that they aren’t for everyone.
They could have a quantity of drawbacks, and you must be cautious to
weigh the benefits and the dangers. Testosterone is the base of most steroid cycles,
and it performs an important function in enhancing
efficiency and muscle progress.
For newbies, it performs an important role in muscle progress, fat loss, and overall performance, making it indispensable for each women and men. Here’s why Testosterone
is important for any cycle, whether or not you’re specializing in bulking or
slicing. The ideal steroid cycle length is decided by your experience
level, goals, and the compounds used. Beginners should start with shorter cycles to attenuate risks,
while superior customers could benefit from extended
cycles tailor-made to their particular goals. No matter the period, proper planning,
monitoring, and post-cycle remedy are important for safe and effective results.
References:
none
Not all dietary supplements, even widespread and normally secure ones,
are suitable for everybody. Caffeine is a stimulant that may enhance
train performance, notably for activities that contain endurance, such as operating.
Scientists have not thoroughly examined it to find out its security.
Sure, Clenbutrol and Winsol can be combined
in a Slicing Stack to enhance muscle definition and vascularity.
Many customers take a hundred and fifty mg throughout an 8‑week cycle and let
the steroid do its work. Your moods and feelings are balanced by the limbic system of your brain.
Simply possessing them illegally (not prescribed to
you by a doctor) can lead to as a lot as a year
in prison and a fantastic of at least $1,000 for a first-time offense.
Over time, having detailed information of
your progress may give you a more tangible sense of how far you’ve come and the way close you are
to achieving your targets. Research has also discovered no long-term well being
effects of utilizing creatine. ‘HGH gut’ is usually observed in IFBB bodybuilders,
which could be attributed to the enlargement of inside organs such as the intestines and
liver (9). From a safety perspective, we find Winsol to
be the higher possibility, with none of the
above side effects being a cause for concern. We have discovered it to be much like Anavar
in regard to its benefits, although slightly extra powerful, causing harsher unwanted effects.
Deca Durabolin is a popular injectable bulking
steroid, typically used in the low season.
Some could find D-Bal to be the most highly effective for muscle gains, whereas others might choose Testo-Max for its capability to spice up
testosterone ranges. Regardless of the selection, it’s necessary to keep in thoughts that utilizing authorized steroids as part
of a comprehensive health plan, together with a correct food
plan and workout regimen, will yield one of the best legal steroid alternatives (mitsfs-wiki.mit.edu) outcomes.
Proof factors to the power of well-formulated supplement blends in boosting athletic performance and muscle positive
aspects. Research shows that authorized steroid options combining multiple performance-enhancing
substances can considerably improve your muscular performance when paired with a
constant exercise routine. The latter is a synthetic type of
testosterone that medical doctors could prescribe to treat sure hormonal or muscle-wasting circumstances.
Individuals typically misuse anabolic steroids to increase muscle mass
and increase athletic performance.
Bear In Mind to speak to your doctor earlier than including
a new supplement to your steroid substitute regimen. As an creator, James is dedicated
to guiding his readers towards optimum health and efficiency, offering actionable insights and strategies through his writings.
For anyone aiming to reinforce their health regime, D-BAL from
Crazy Bulk is my high advice. Nonetheless, with no well-rounded diet,
their potential benefits could additionally
be considerably diminished. See, it all comes down to working out what sort of
elements you want and then how much of each of them is in each scoop or capsule.
Then you’re employed out what quantity of doses you need on your targets, and
you will perceive how much it will cost daily. At the same
time, a powder supplement isn’t always convenient if
you have to take it at specific instances of the day whenever you
may not have a shaker to mix up the powder.
How steroids work in the physique is by binding to the androgen receptor.
This can end result in increased protein synthesis, nitrogen retention, and anabolic exercise.
The steroids connect to the receptors and once they are there it
causes a domino impact that increases muscle mass.
Authorized steroids are a valuable software for anyone passionate about health,
especially bodybuilders and athletes who wish to improve their efficiency
safely and effectively. We scrutinized scientific research, medical trials, and
peer-reviewed literature to validate the protection of every ingredient
within the authorized steroids.
In Contrast To illegal anabolic steroids that depend on synthetic
hormones and chemical brokers, CrazyBulk
formulas are rooted in natural, well-researched elements.
These components are carefully selected for their capacity to help key health objectives like energy, endurance, muscle recovery, fat metabolism, and hormonal stability
– all without the cruel side effects. These elements are
rigorously selected for their ability to assist key fitness targets
like power, endurance, muscle restoration, fat metabolism,
and hormonal balance — all without the harsh unwanted facet effects.
Secure alternate options to anabolic steroids are sometimes called authorized steroids.
These dietary supplements are formulated with natural components that purpose to mimic the muscle-building
effects of anabolic steroids with out inflicting dangerous unwanted effects.
Examples of such alternate options include
D-Bal, Trenorol, Anvarol, and Testo-Max.
Understanding the authorized status of steroids in bodybuilding is crucial.
Consult with medical professionals earlier than considering
any substances. Keep knowledgeable and make safe, legal choices
on your bodybuilding journey. Balancing well being and efficiency
is essential for a sustainable career.
In one of many few research of healthy volunteers, Dr.
Kjaer gave males in their 20s injections of HGH and in contrast muscle growth to that of males who received a placebo.
Your HGH results will be made or damaged by the standard you should
purchase. Once More, this comes right down to price and the power to supply LEGITIMATE or top-quality generic HGH kits (of which
there are very few). Otherwise, stick along with your AAS
plan for now, and I’ll guess there’s much more you can get out of your steroid
cycles while you wait until you’re able to do HGH the right way.
If you don’t have a quantity of thousand dollars to spend,
then in all probability not. To use HGH primarily for muscle progress purposes, you’ll desire a
naked minimal of 12 weeks.
Since anabolic steroids are synthetic and have important
dangers, this can lead folks to turn to pure alternate options.
They offer a broad range of dietary and well being supplements, however only legal over-the-counter merchandise.
Instead of steroids, you can see many options for
dietary supplements designed to build muscle, shed weight, boost power, and extra.
DBulk is a powerful muscle-building complement that is
meant to assist individuals attain their fitness objectives.
It was particularly formulated to help people gain high quality lean muscle mass
and power, whereas simultaneously supporting the expansion of new muscular tissues.
To maximize results, legal steroids ought to be paired with a structured workout routine and
a nutrient-rich food regimen.
If fats loss is on your agenda, this stack may help you obtain that as
well, and also you won’t have to fret about
dropping muscle – all these compounds ensure you keep in a optimistic anabolic state.
Total, muscle gains can be anywhere from 10 lbs and
up, and we know from studies that even at very low
doses of 1mg of LGD 4033, muscle gains can be made shortly.
MK-677 can lead to some water retention, which
is a short lived effect but one to remember as you consider your results throughout this
cycle. LGD-4033 will allow you to put on spectacular dimension and see a notable enchancment in muscle power, so you’ll be succesful of raise heavier and enhance the intensity and length of your exercises.
Some skilled feminine bodybuilders settle for these risks for aggressive
success, but most women purpose to avoid them.
To contextualize, this a hundred and fifty mg dose is six instances the suggested dose of 25mg per day
and triple the dose that provides vital outcomes for male bodybuilders,
who often take around 50mg per day. Notably, the only unwanted effects reported by ladies on this excessive dosage had been reduced libido and increased tiredness, likely due to lower pure testosterone manufacturing.
The purpose of post-cycle remedy (PCT) for men who use anabolic steroids
is to support and promote the restoration of normal testosterone manufacturing that has been curtailed or shut down by the use of steroids.
Stenabolic, with its very quick half-life, should be taken as
much as 3 times daily to take care of its effects.
If prednisolone side effects turn into difficult to tolerate, discuss together
with your doctor about coping tips or other treatment options.
MG exacerbation in the past 6 months was extra frequent in the group with intolerable AEs,
and MG-QOL15 and MG-ADL sum scores were significantly larger (worse) compared with the no insupportable AE group (table 4).
Prednisone is a first-line immunosuppressive therapy for myasthenia gravis (MG), whereas
short-term and long-term opposed effects (AEs) are a limiting factor in its
utilization. Utilizing steroids over an extended period of time may end up
in irreversible harm to the organs and feminine reproductive system.
This is a novel impact in comparison with other anabolic
steroids, which generally decrease subcutaneous fats while growing visceral fat (5).
We hypothesize that this is due to Anavar enhancing insulin sensitivity (6), whereas other steroids lead to an individual becoming much less delicate to insulin (7), probably leading to steroid-induced diabetes.
Although Anavar is less prone to cause androgenic side effects
compared to different steroids, it could still cause them in some girls.
These include the event of masculine options corresponding to excessive physique hair, a deepened voice,
and an enlarged clitoris. These anti-inflammatory steroids are different from the anabolic steroids some athletes use to achieve an unfair competitive benefit.
Nonbinary individuals also can use nandrolone, an injectable
steroid, to extend muscle mass without excessive
hair development. However, its security profile just isn’t properly studied for medical
use, as most knowledge comes from its misuse in athletes.
The cardiovascular unwanted facet effects of Primobolan will primarily revolve round ldl cholesterol, both the suppression of HDL ldl cholesterol and enhance in LDL
cholesterol. The total impact on ldl cholesterol may be fairly significant,
much larger than most injectable steroids, but a lot lower than most oral steroids.
In order to protect your health, in case you have high cholesterol
you ought to not supplement with this steroid until your cholesterol is under control
and you’ve got got been cleared by your doctor. If you would possibly be wholesome
enough for use, you must ensure you do all you possibly can to promote the continuation of healthy
ldl cholesterol. This means your diet should be rich in omega fatty acids, low in simple sugars
and saturated fat; daily fish oil supplementation is advised.
Nonetheless, with correct use many men can avoid the unwanted effects of Masteron and enjoy all
this hormone has to supply. We find that ladies taking a small dose of 5 mg per day will discover fats loss and enhanced muscle mass in the first 10 days.
They also expertise a big increase in energy and motivation in the first three days.
However, if Winstrol is used in average to low doses in short
cycles, the danger of creating long-term unwanted
effects is greatly reduced compared to those that abuse this steroid.
It stops your immune system from producing certain chemicals that would normally cause inflammation. Prednisone is used to reduce irritation (swelling) and overactivity in your immune system.
Medical Doctors prescribe it to treat a wide variety of inflammatory and autoimmune health circumstances.
This is a useful technique, significantly for
cutting and shredding (where Anavar excels). However,
it isn’t doubtless to be used in pure bulking cycles because there’s a
limit to just how excessive your dose of Anavar ought to be before health risks
kick in. While Anavar has gentle natural testosterone suppression effects, it not often absolutely suppresses or even suppresses at half the pure levels.
Hence, the decrease in SHBG is still highly helpful
regardless of your testosterone levels when using this steroid.
This anabolic steroid doesn’t aromatize and isn’t a progestin making gynecomastia and water
retention unimaginable. In fact, the Drostanolone hormone has
been proven to have pretty robust anti-estrogenic effect.
Age – Associated to genetic response altering over time, age is a very important
issue as as to if or not an individual will experience a facet
impact and the way severe it is going to be. For example,
varied people could possibly run aromatizable anabolic Steroid Alternatives That Work cycles with no aromatase inhibitor or Estrogen blocker and expertise no gynecomastia symptoms.
15 years later, this identical individual could run a similar
cycle and abruptly experience gynecomastia development.
This is indicative that the person’s physique has modified with age
and is now reacting in a really different method to the results of
anabolic steroids. The sensationalist and biased mass
media would have us believe that anabolic steroids are extremely high-risk drugs that are the trigger of acute
death as nicely as long-term demise. This could not be farther
from the reality, because the medical establishment regards anabolic
steroids as low-risk therapeutic compounds with a high degree of safety.
So many factors influence your results when utilizing this (or any other) steroid.
Masteron is understood to be a greater temper enhancer than Anavar, however this effect could be very individual-dependent.
Most Masteron users may even see the next enhance to the libido than is usually experienced
with Anavar. On the draw back for Masteron, it dries out the joints and
can cause joint pain, whereas Anavar may be joint supportive to a level.
I’ve seen loads of feedback about Anavar users experiencing joint ache – this may be another unlucky consequence of “fake”
Anavar. Anavar is the clear winner if avoiding joint discomfort is a precedence.
As Quickly As again, if you are delicate or do not want to danger it, persist with the beginner plans listed above.
However, you may not be able to spot them when the bodybuilders take the stage
since they often have a heavy spray tan on. For instance, Trenbolone-based steroids are used to build muscle
and improve muscular power, while Clenbuterol-based steroids
help shed extra fat. You can also mix two or extra compatible steroids to
expertise a variety of benefits, provided they don’t render any antagonistic side effects on your
body. Furthermore, it is essential to consider the potential negative health impacts of anabolic steroids.
Despite enhancements in physique composition, there can be underlying cardiac or hepatic damage occurring that we often detect.
Dianabol is a steroid that can add up to 50 kilos of mass to customers
when cycled a number of instances and stacked with other
bulking steroids. He praised pure coaching on bodybuilding.com, opposed steroid utilization, and claimed that everybody who can’t do what he did is “lazy”
or an “underachiever”.
Nonetheless, we discover the degree of fats loss is often determined
by a user’s eating habits. For instance, those that are bulking typically
will eat in a generous calorie surplus to assist muscle and energy results.
This will contribute to some fat achieve and thus blunt Dianabol’s fat-burning impact.
We generally see Dianabol taken as a first steroid cycle
as a result of newbies wanting significant results quick.
Nevertheless, Dianabol is probably extra appropriate
for intermediate steroid users due to its antagonistic effects on cholesterol and liver enzymes.
Although it’s one of the highly effective steroids on the market, Anadrol additionally comes with a bunch of nasty side effects.
Hone is an online clinic that helps men and women handle their health.
As part of your subscription and as medically indicated, physicians prescribe medications, and recommend
dietary supplements that are delivered to you from the consolation of your own home.
Matthew was all the time laser-focused on his well being, attaining a master’s diploma in train physiology
and dealing as a strength and conditioning coach.
But his vitality took a nose-dive in his thirties, which just about value him his new enterprise as a real property agent.
He is now dedicated to optimizing other areas of his well being in order that he can age higher.
Tren is a true game-changer for bodybuilders, thanks to its exceptional
effects on muscle improvement, slicing phases, and general
performance. As an anabolic steroid, Trenbolone
possesses potent properties that drive important muscle development.
It stimulates protein synthesis and nitrogen retention, leading to accelerated
positive aspects in lean muscle mass. Bodybuilders who incorporate Trenbolone into their coaching routine typically expertise speedy and substantial
will increase in muscle dimension and power. Tren exerts its
highly effective results via a number of mechanisms, making it one of the most
potent anabolic steroids out there. Firstly, Tren enhances nitrogen retention within muscle tissues, resulting in an increased synthesis of proteins.
This heightened protein synthesis helps muscle development
and restore, permitting people to expertise accelerated features in lean muscle
mass.
Anabolic steroids have turn into the go-to for these seeking important physique metamorphosis.
A quick search online will flood your display screen with before-and-after pictures showcasing the consequences of steroids, adopted
not only by everyday people but additionally by celebrities and elite athletes.
I was also doing 16/8 intermittent fasting which made it
easier to eat much less.
On its own, Deca Durabolin can enhance the fluid levels on the intracellular level and promote your anabolic course of.
For example, it may possibly assist with sooner muscle recovery time,
increase endurance, increase the pure production of RBCs, and so on. Deca Durabolin is among the milder steroids that work
finest when mixed with different potent bulking steroids like Dianabol and Testosterone in the off-season. This is as
a end result of it doesn’t really contribute to the enlargement of muscles when used individually.
With everything stated and done, it’s
finally time to reply the burning question- how do
bodybuilders look earlier than and after utilizing steroids?
And for this, we now have considered a number of the hottest steroids utilized by bodybuilders all all over the world.
In our experience, ladies usually construct 7–10
lbs of muscle on Anavar whereas notably reducing visceral and
subcutaneous fat stores. I’m not utilizing this example to say that
every one people who generate income within the fitness trade
are steroid users. In reality, a lot of fitness models do use steroids,
as a result of it’s extraordinarily difficult to
maintain a shredded physique year around.
It’s exhausting for many of us to imagine a life where you can lie,
steal and abuse others with out feeling even slightly bit guilty because we’ve empathy.
According to The Sociopath Subsequent Door, 1/25 persons are estimated to be sociopaths
and heaps of of them are present in high positions in their industries together with the health trade.
The guy achieved a GREAT physique and currently has
an instagram with about 30K followers.
Due To This Fact, liver-compromised people should avoid methandrostenolone.
Consuming alcohol must be avoided on Dianabol, with studies showing it to be hepatotoxic and thus rising
the possibilities of liver injury (Wilder, 1962). When the liver is excessively strained, we
discover the body reduces hunger. This acts as a self-defense mechanism, reducing
the load on the organ as it actually works to process food.
References:
steroids.com review (newslabx.csie.ntu.edu.tw)
Likewise, you’ll achieve better power achieve through bench presses, squats,
and deadlifts. First-time steroid customers are suggested to comply with a few 4 to 6-week cycles with sufficient off-cycle time in between to
help their our bodies get accustomed to the different compounds.
After this, they may prolong the cycle to 8,10, or a maximum
of 12 weeks if required. Male customers (even beginners) usually need stronger doses of Anavar because of the naturally high testosterone ranges.
Users may also carry out common cardiovascular train, in combination with weight training, to maintain blood strain ranges down. We have found that
supplementing with fish oil also helps to scale back such strain by lowering triglycerides.
Dosages of 4 g/day have efficiently handled coronary artery illness and
decreased incidents of sudden cardiac dying (2). Anavar dramatically will increase protein synthesis, nitrogen retention, and IGF-1 (insulin-like development factor) ranges,
causing significant enhancements in muscle hypertrophy (size) and energy.
This article details steroid cycles that are not only tailor-made for women however, most significantly, optimized for hurt discount.
SARMs, subsequently, require a longer-term strategy to their use, however on the upside, they don’t come with the identical drastic unfavorable impact on your hormonal system and overall health that steroids do.
Theoretically, SARMS shouldn’t show a lot of the antagonistic results of
steroids because of their strict tissue selectivity. However as a outcome of SARMs aren’t yet perfected, we are in a position to and do experience some of the undesirable side effects that you would otherwise attempt to
avoid by not utilizing anabolic steroids.
After all, that’s one of their main promoting factors within the bodybuilding community!
You should consider SARMs extra dangerous than steroids till
we all know much more about their longer-term effects.
Past Anavar other steroids that can be used by ladies embody Primobolan Depot and Winstrol; Primobolan Depot being primary.
Each of those steroids can be utilized efficiently, however it must be noted the probability of
virilization is greater with these steroids than Anavar. Even so,
you must remember what we discussed above about combating virilization, and should you can hold to these principles you will be
fine. Some girls will merely not be able to touch these steroids
but some will. If you may be in search of a selected SARM, I’d say 10-20mg/day Cardarine for
eight weeks. Another option is to do an Anavar cycle
at 10mg/day (split Anavar into two doses daily at 5mg/each, as quickly
as with breakfast and again earlier than bedtime) for eight weeks.
With each choices, get off as much fats as you’ll have the
ability to naturally, hit the cardio hard, and then use certainly one of them.
In our expertise, profitable Anavar dosages for girls vary from 5 to 10 mg/day.
Nonetheless, if customers are consuming copious amounts of alcohol
on-cycle, taking poisonous drugs, or stacking Anavar with other orals
(such as Anadrol or Winstrol), then cirrhosis or peliosis hepatis are both potential.
Thus, Anavar is not strongly hepatotoxic in comparability with other oral steroids.
We have had success in accelerating the recovery of women’s endogenous testosterone when supplementing with
DHEA, the official prescription treatment for girls with low
androgen levels. Thus, many steroids will cause less fats
on the surface (externally), but on the expense of a
bloated midsection (even when lean). Muscular power may also drastically enhance because of enhanced
ATP (intracellular adenosine triphosphate) manufacturing and better levels of exogenous testosterone,
enhancing protein synthesis. Realistically, ladies sometimes construct
approximately 12 lbs of muscle from their first Anavar cycle, in our experience.
At the bottom of the article each reference might be linked to a peer-reviewed
examine or paper. This article is based on scientific evidence,
written by experts and fact checked by professionals in this
subject. All Steroidal.com content is medically reviewed and truth checked to ensure as a lot factual accuracy as attainable.
She also made the comment that after she did some careful analysis on the results Turinabol could
have on girls and talked about she would
by no means be willing to use a substance like that which could probably be dangerous.
Fragkou denied the usage of this steroid and claimed she only took dietary
dietary supplements and claims she was still puzzled on how she examined positive.
Below is a list of ladies who have been suspended or banned from
Crossfit because of steroid use, in a few of the cases ladies declare foul play but there isn’t a real method to
decide a method or one other.
“I came second in the Swedish championship and I had cheated by eating 4 grapes two weeks before the competition. It wasn’t really dishonest as a outcome of everyone else did it too, but I felt it was cheating and I came second in that competitors. Earlier Than, I couldn’t even use lip balm because it contained fats and I was afraid of getting it into my body. I was so afraid of every little closest thing to steroids On the market that would sabotage a food plan or
a dedication, as a outcome of it meant my complete life to me”. Despite hard training and using AAS, girls should really feel that they aren’t reaching what they want.
Anadrole is probably top-of-the-line steroids that offers women the most effective bang for their money. Its primary function is that can help you achieve muscle and strength and if that’s not enough you presumably can always stack it with other popular legal steroids for an improved physique. Basically, the dose of prednisone could be “higher” and it won’t go away the physique as shortly, so you could expertise extra of the unwanted effects on this record. “It’s at all
times a good idea to have a list of all of the drugs you’re taking available in your doctor,” she says. In this article, discover out what to expect with steroid-induced hair fall and what you can do about it.
This have to be carried out because girls are more susceptible than males to the negative results of AAS and are more vulnerable to unwanted aspect effects (Strauss et al., 1985; Gruber and Pope, 2000). It was essential for the women on this examine to maintain their femininity and regulate the dimensions of their muscles. Sturdy, muscular women usually are not perceived as female and aren’t an accepted norm in society.
Another widespread strategy is to stack a dry SARM with one that promotes fats loss. This creates a chopping or contest prep stack involving dry SARMs like Ostarine, RAD-140, or S4 combined with SR-9009 or Cardarine. It can mimic the features of ghrelin, which boosts IGF-1 and progress hormone levels.